我正在尝试检测这些价格标签文本,它们通常已经过明显的预处理。虽然可以轻松读取其上方写的文本,但无法检测价格值。我正在使用Python绑定pytesseract,但它也无法从CLI命令中读取。大多数情况下,它试图将价格识别为一个或两个字符的部分。
示例1:

tesseract D:\tesseract\tesseract_test_images\test.png output
这个样例图片的输出如下:
je Beutel
13
然而,如果我将价格裁剪并拉伸,使它们看起来分开且字体大小相同,则输出就很好。
处理后的图像(裁剪和缩小价格):

je Beutel
1,89
如何使OCR Tesseract按我的意愿工作,因为我将处理大量相似的图像?
编辑:添加了更多的价格标签:


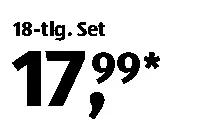 sample5 sample6 sample7
sample5 sample6 sample7


{kind=link}
{kind=link}
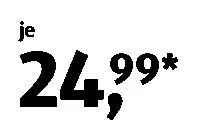{kind=link}
cv2.connectedComponents和cv2.boundingRect函数来检测同一水平区域上大小不同的连通区域。然后可以通过放大较小的区域、缩小较大的区域或单独隔离不同的区域并分别进行调用tesseract。 - dROOOze