我正在开发一个Python脚本,用于查询多个不同的数据库以整合数据并将其持久化到另一个数据库中。 该脚本从大约15个不同的数据库中收集潜在数百万条记录的数据。为了尝试加快脚本的速度,我包含了一些缓存功能,这归结为具有某些频繁查询数据的字典。该字典包含键值对,其中键是根据数据库名称、集合名称和查询条件生成的哈希,而值是从数据库检索到的数据。例如:
在本地字典中保存此数据意味着,我可以在本地访问一些频繁查询的数据,而不必每次都查询数据库(这可能很慢)。如上所述,有很多查询,因此字典可能会变得相当大(几个千兆字节)。 我有一些代码使用
{123456789: {_id: '1',someField: 'someValue'}} ,其中123456789 是哈希,{_id: '1',someField: 'someValue'} 是从数据库检索到的数据。在本地字典中保存此数据意味着,我可以在本地访问一些频繁查询的数据,而不必每次都查询数据库(这可能很慢)。如上所述,有很多查询,因此字典可能会变得相当大(几个千兆字节)。 我有一些代码使用
psutil查看运行脚本的机器上可用的内存量,如果可用内存量低于某个阈值,则清除字典。清除字典的代码如下:cached_documents.clear()
cached_documents = None
gc.collect()
cached_documents = {}
需要指出的是cached_documents是一个本地变量,它被传递到所有访问或添加缓存的方法中。不幸的是,即使调用上述代码后,Python仍然会持有大量额外的内存,这似乎并不足够释放内存。您可以在此处查看内存使用情况概要:
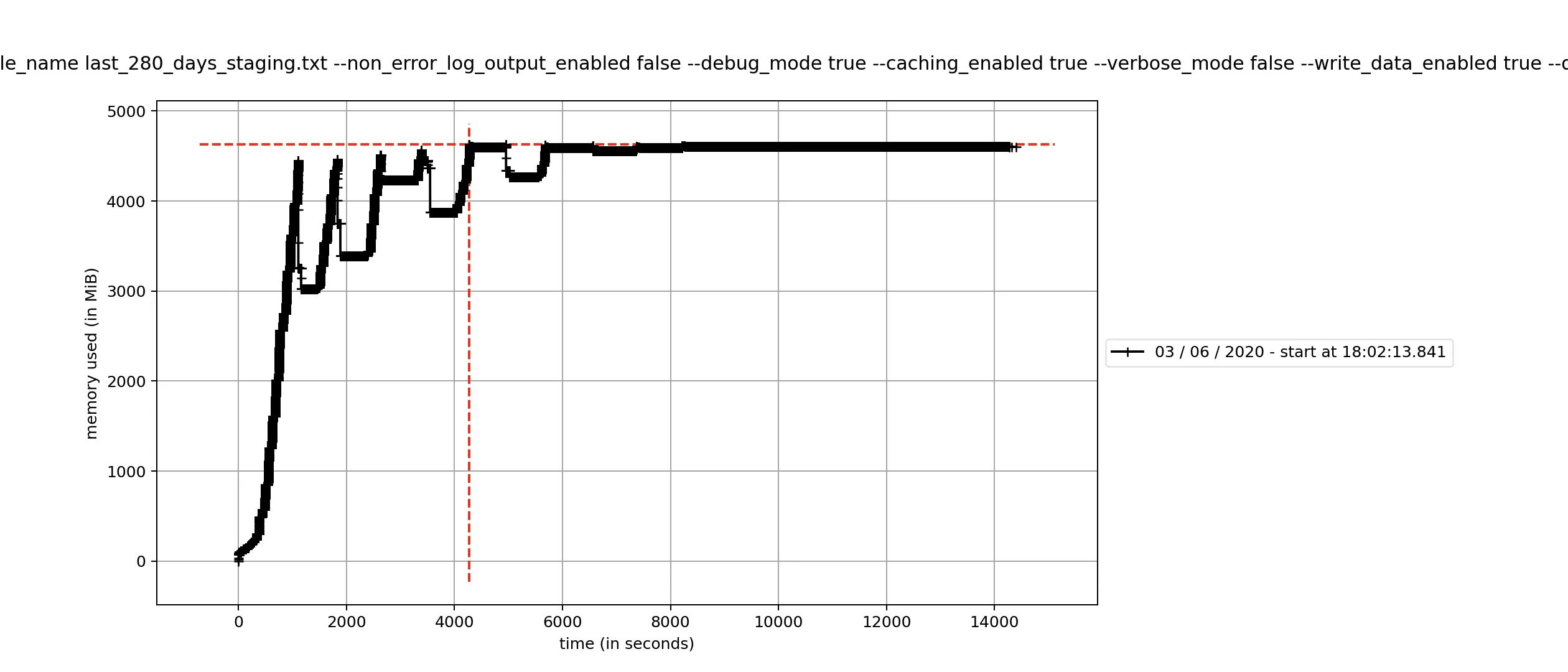
值得注意的是,在清除字典的前几次中,我们将释放大量内存回归系统,但每个后续时间似乎都变少了,此时由于Python持有大量内存,可用内存处于阈值内,因此缓存会极频繁地清除而导致内存使用率趋平。是否有办法在清空字典时强制Python正确释放内存,以避免这种趋平现象?任何提示都将不胜感激。
namedtuple或者一个带有槽的类,就像这样{hash_value: namedtuple_record}。 - juanpa.arrivillagaRecord = namedtuple('Record', 'id some_field'),然后cached_documents[hash_doc(document)] = Record(id, some_field_val)等... - juanpa.arrivillaga