我想使用管理命令对马萨诸塞州的建筑进行一次性分析。我将问题代码简化为一个8行代码段,以演示遇到的问题。注释只是解释我为什么要这样做。我正在原样运行以下代码,在一个空白的管理命令中。
似乎
因此,我的问题是:当Python超出范围时,如何强制释放Django模型列表? 编辑:我觉得在stackoverflow上有一个小陷阱--如果我写得太详细,没有人愿意花时间去阅读它(它变成了一个不太适用的问题),但如果我写得太少,我会冒着忽略问题的风险。无论如何,我真的很感谢这些答案,并计划在这个周末终于有机会回到这个问题时尝试一些建议!!
我想使用管理命令对马萨诸塞州的建筑进行一次性分析。我已经将有问题的代码简化成一个8行代码片段,以演示我遇到的问题。注释仅解释我为什么要这样做。我在一个否则空白的管理命令中原封不动地运行以下代码:
zips = ZipCode.objects.filter(state='MA').order_by('id')
for zip in zips.iterator():
buildings = Building.objects.filter(boundary__within=zip.boundary)
important_buildings = []
for building in buildings.iterator():
# Some conditionals would go here
important_buildings.append(building)
# Several types of analysis would be done on important_buildings, here
important_buildings = None
print('mem', process.memory_info().rss)来检查内存使用率)。似乎
important_buildings列表占据了大量内存,即使超出范围。如果我用_ = building.pk替换important_buildings.append(building),它就不再消耗太多内存,但是我确实需要这个列表进行一些分析。因此,我的问题是:当Python超出范围时,如何强制释放Django模型列表? 编辑:我觉得在stackoverflow上有一个小陷阱--如果我写得太详细,没有人愿意花时间去阅读它(它变成了一个不太适用的问题),但如果我写得太少,我会冒着忽略问题的风险。无论如何,我真的很感谢这些答案,并计划在这个周末终于有机会回到这个问题时尝试一些建议!!
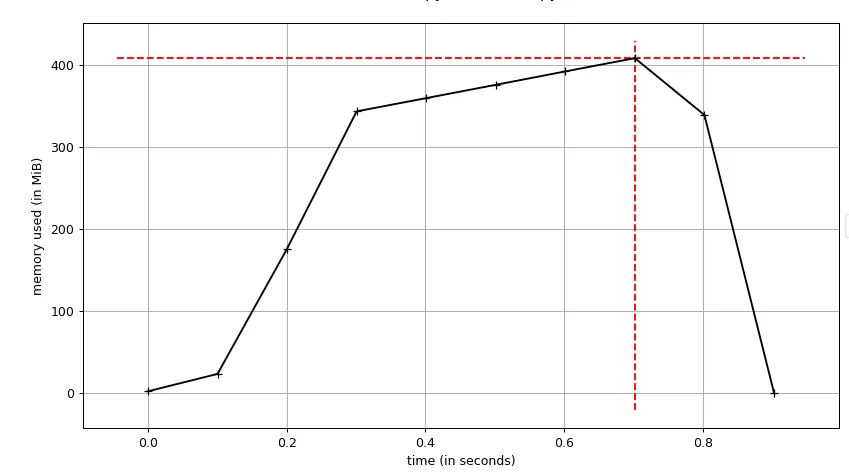
building实例之间创建引用,从而导致引用循环,阻止gc执行其工作? - Laurent Sprocess.memory_info().rss的工作原理。结果证明,在上面的片段中没有内存问题。出于这个原因,我授予了完整的赏金。 - Teddy Ward