1. 按顺序删除子序列
我们有一组值,例如
[1,5,1,3,4,2,3,2,1,3,1,2],还有一个要从第一组序列中删除的值的子序列,例如
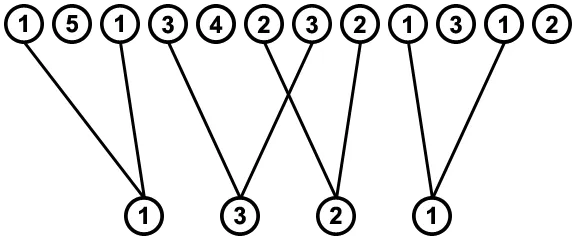
[1,3,2,1]。 如果我们找到每个值实例在序列中所处的位置,则可以得到以下图表:
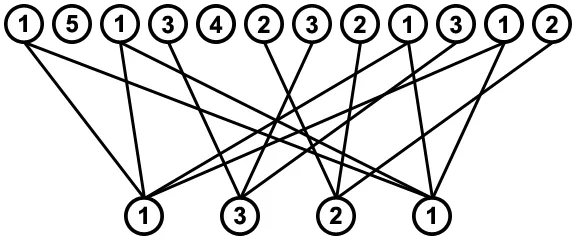
寻找按顺序从序列中移除值的所有方法,意味着要找到底部行中待删除值与序列实例相连的所有方式,而且不能有任何线交叉,例如:
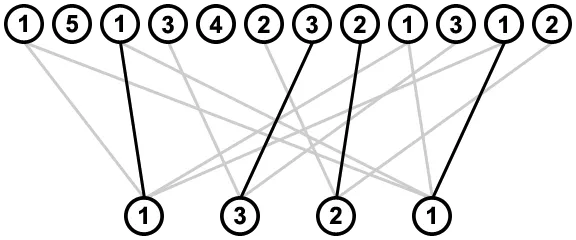
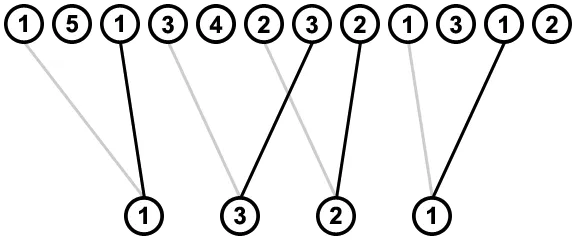
为避免以不导致有效解决方案的方式删除值(例如,从最右边的值1开始删除,之后没有值3可以被删除),我们将首先删除所有导致这种无效解决方案的图中的连接。
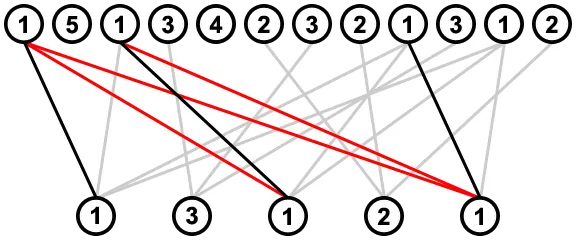
这将通过两次迭代子序列来完成。首先我们从左到右进行此操作,对于每个值,我们查看其最左侧的连接,并删除任何与该连接相遇或交叉的值到其右侧的连接;例如,在考虑从值2的最左侧连接时,从其右侧的值1中删除了两个连接(用红色表示),因为它们穿过了这个连接:
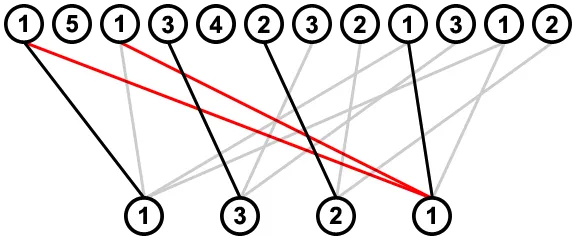
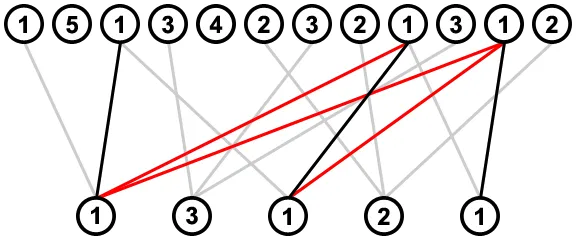
在下一步中,我们从右向左进行,对于每个值,我们查看其最右侧的连接,并删除来自其左侧值的任何与该连接相遇或交叉的连接;例如,在考虑右侧值为1的最右侧连接时,将删除其左侧值为2的最右侧连接(用红色表示),因为它与此连接相交:
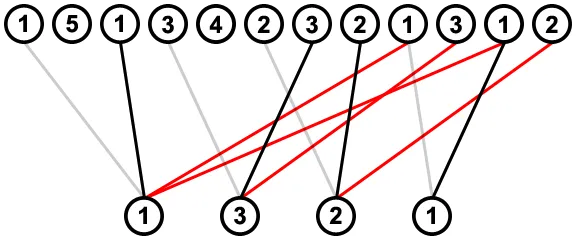
我们最终得到了下面简化的图表。通过将子序列中每个值的每个连接实例组合在一起,使用例如递归:您迭代子序列中第一个值的选项,并且每次都将其余的子序列与之递归,以便将第一个值的选项与其他值的所有选项组合在一起。
简化图中可能存在交叉连接,但这些不再成问题。在示例中,即使为值3选择了正确的连接,仍存在一个值2的连接与其不相交:
将此转化为代码相对简单;在代码片段下面,您将找到使用示例数据的代码运行过程。
function removeSubSeq(seq, sub) {
var posi = [];
sub.forEach(function(elem) {posi[elem] = []});
seq.forEach(function(elem, index) {if (posi[elem]) posi[elem].push(index)});
var conn = sub.map(function(elem) {return posi[elem].slice()});
for (var i = 1; i < conn.length; i++) {
var left = conn[i - 1][0];
while (conn[i][0] <= left) {
conn[i].shift();
}
}
for (var i = conn.length - 2; i >= 0; i--) {
var right = conn[i + 1][conn[i + 1].length - 1];
while (conn[i][conn[i].length - 1] >= right) {
conn[i].pop();
}
}
var combinations = [], result = [];
combine(0, -1, []);
for (var i = 0; i < combinations.length; i++) {
result[i] = seq.slice();
for (var j = combinations[i].length - 1; j >= 0; j--) {
result[i].splice(combinations[i][j], 1);
}
}
return result;
function combine(step, prev, comb) {
for (var i = 0; i < conn[step].length; i++) {
var curr = conn[step][i];
if (prev >= curr) continue;
if (step + 1 == conn.length) combinations.push(comb.concat([curr]));
else combine(step + 1, curr, comb.concat([curr]));
}
}
}
var result = removeSubSeq([1,5,1,3,4,2,3,2,1,3,1,2], [1,3,2,1]);
for (var i in result) document.write(result[i] + "<br>");
代码执行以下步骤:
posi[1] = [0,2,8,10], posi[2] = [5,7,11], posi[3] = [3,6,9]}
创建一个二维数组,将子序列中的位置与序列中的位置相对应:
conn = [[0,2,8,10],[3,6,9],[5,7,11],[0,2,8,10]]
conn = [[0,2,8,10],[3,6,9],[5,7,11],[8,10]]
conn = [[0,2],[3,6],[5,7],[8,10]]
combinations = [[0,3,5,8],[0,3,5,10],[0,3,7,8],[0,3,7,10],
[0,6,7,8],[0,6,7,10],[2,3,5,8],[2,3,5,10],
[2,3,7,8],[2,3,7,10],[2,6,7,8],[2,6,7,10]]
使用组合来从序列的副本中删除值(请参见代码片段输出)。
2. 删除无序值列表
如果要删除的值列表不一定是主序列的子序列,并且可以按任意顺序删除这些值,则可以使用与上面相同的方法,但是交叉连接规则有所放松:
从位置列表中删除交叉连接,并在生成组合时避免交叉连接,只需要针对相同的值进行操作。
在此示例中,仅删除重复值1的交叉连接;首先从左到右:
然后从右到左:
导致简化后的图形,将值为1的有问题的交叉连接移除,而值为2和3的交叉连接保留:
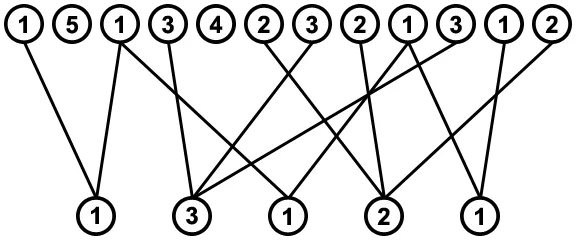
下面是一个编程示例,改编自子序列版本; 代码中只有几行被更改,如注释所示(我还使用了不同的方法来从序列中删除值)。要删除的值列表在开始时进行排序,以便相同的值被分组在一起,易于跟踪相同的值。
function removeSubList(seq, sub) {
sub.sort(function(a, b) {return a - b});
var posi = [];
sub.forEach(function(elem) {posi[elem] = []});
seq.forEach(function(elem, index) {if (posi[elem]) posi[elem].push(index)});
var conn = sub.map(function(elem) {return posi[elem].slice()});
for (var i = 1; i < conn.length; i++) {
if (sub[i - 1] != sub[i]) continue;
var left = conn[i - 1][0];
while (conn[i][0] <= left) {
conn[i].shift();
}
}
for (var i = conn.length - 2; i >= 0; i--) {
if (sub[i] != sub[i + 1]) continue;
var right = conn[i + 1][conn[i + 1].length - 1];
while (conn[i][conn[i].length - 1] >= right) {
conn[i].pop();
}
}
var combinations = [], result = [];
combine(0, -1, []);
for (var i = 0; i < combinations.length; i++) {
var s = seq.slice();
combinations[i].forEach(function(elem) {delete s[elem]});
result[i] = s.filter(function(elem) {return elem != undefined});
}
return result;
function combine(step, prev, comb) {
for (var i = 0; i < conn[step].length; i++) {
var curr = conn[step][i];
if (prev >= curr && seq[prev] == seq[curr]) continue;
if (step + 1 == conn.length) combinations.push(comb.concat([curr]));
else combine(step + 1, curr, comb.concat([curr]));
}
}
}
var result = removeSubList([1,5,1,3,4,2,3,2,1,3,1,2], [1,3,1,2,1]);
for (var i in result) document.write(result[i] + "<br>");