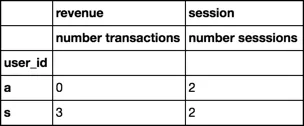
一个pandas dataframe df有三列:
user_id,
session,
revenue
现在我想按照唯一的user_id分组,并派生出两个新列——一个称为number_sessions(计算与特定user_id相关联的会话数),另一个称为number_transactions(计算每个user_id下具有值> 0的revenue列行数)。 我该如何做到这一点?
我尝试了这样做:
我尝试了这样做:
df.groupby('user_id')['session', 'revenue'].agg({'number sessions': lambda x: len(x.session),
'number_transactions': lambda x: len(x[x.revenue>0])})