我试图运行以下代码,但是报告了一个错误:
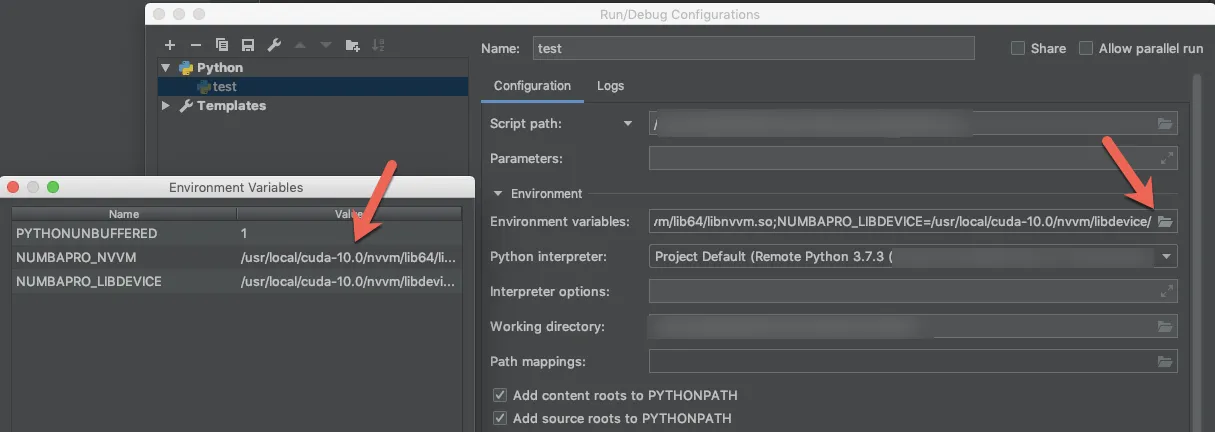
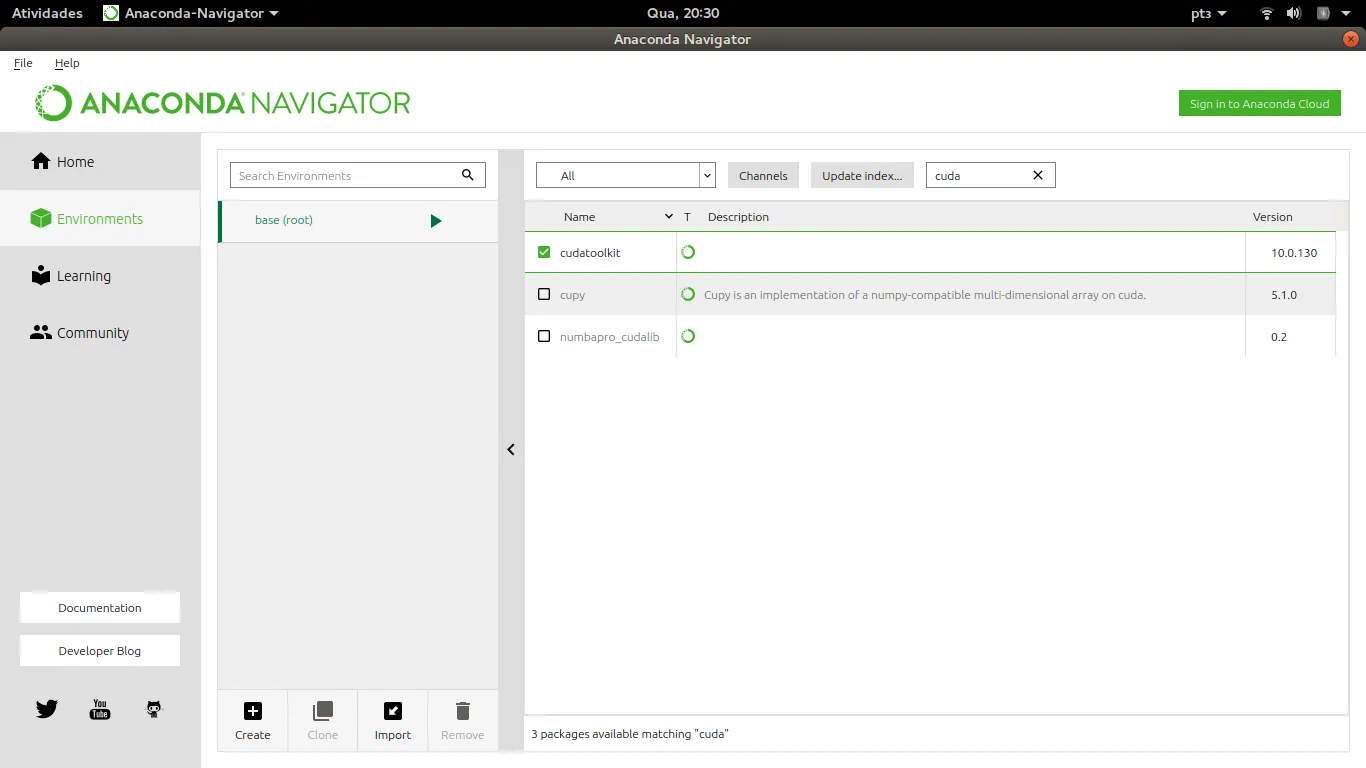
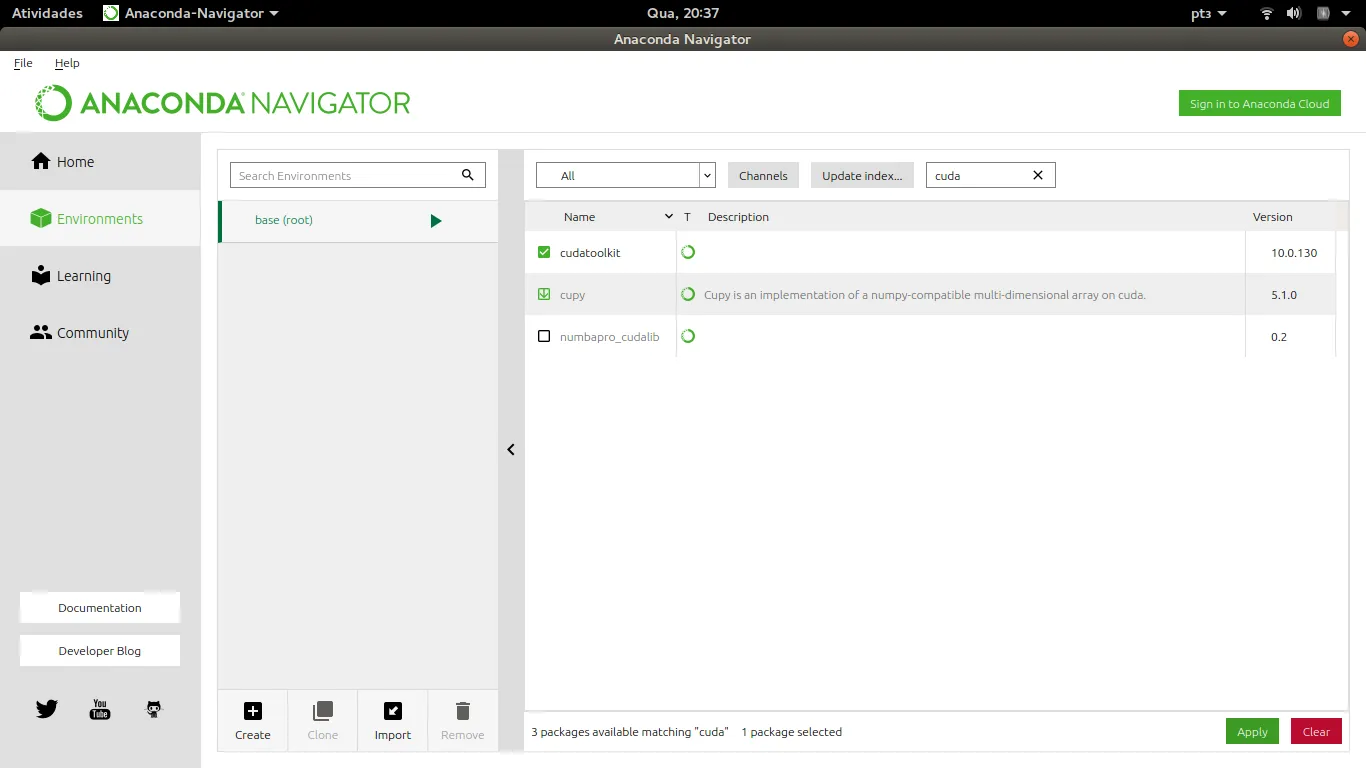
NvvmSupportError: 找不到 libNVVM。请执行 conda install cudatoolkit:未找到库 nvvm。
我的开发环境是:Ubuntu 17.04,Spyder/Python3.5,并且我已通过 conda 安装了 numba 和 cudatoolkit。Nvidia 显卡 (GTX 1070 和 GTX 1060)。
import numpy as np
from timeit import default_timer as timer
from numba import vectorize
@vectorize(["float32(float32, float32)"], target='cuda')
def VecADD(a,b):
return a+b
n = 32000000
a = np.ones (n, dtype=np.float32)
b = np.ones (n, dtype=np.float32)
c = np.zeros(n, dtype=np.float32)
start = timer()
C = VecADD(a,b)
print (timer() - start)
有人知道如何解决这个问题吗?