这是我的测试代码:
from keras import layers
input1 = layers.Input((2,3))
output = layers.Dense(4)(input1)
print(output)
输出结果为:
<tf.Tensor 'dense_2/add:0' shape=(?, 2, 4) dtype=float32>
但是发生了什么?
文档中说:
注意:如果层的输入秩大于2,则在与内核进行初始点积之前将其展平。
而输出则被重新塑形?
这是我的测试代码:
from keras import layers
input1 = layers.Input((2,3))
output = layers.Dense(4)(input1)
print(output)
输出结果为:
<tf.Tensor 'dense_2/add:0' shape=(?, 2, 4) dtype=float32>
但是发生了什么?
文档中说:
注意:如果层的输入秩大于2,则在与内核进行初始点积之前将其展平。
而输出则被重新塑形?
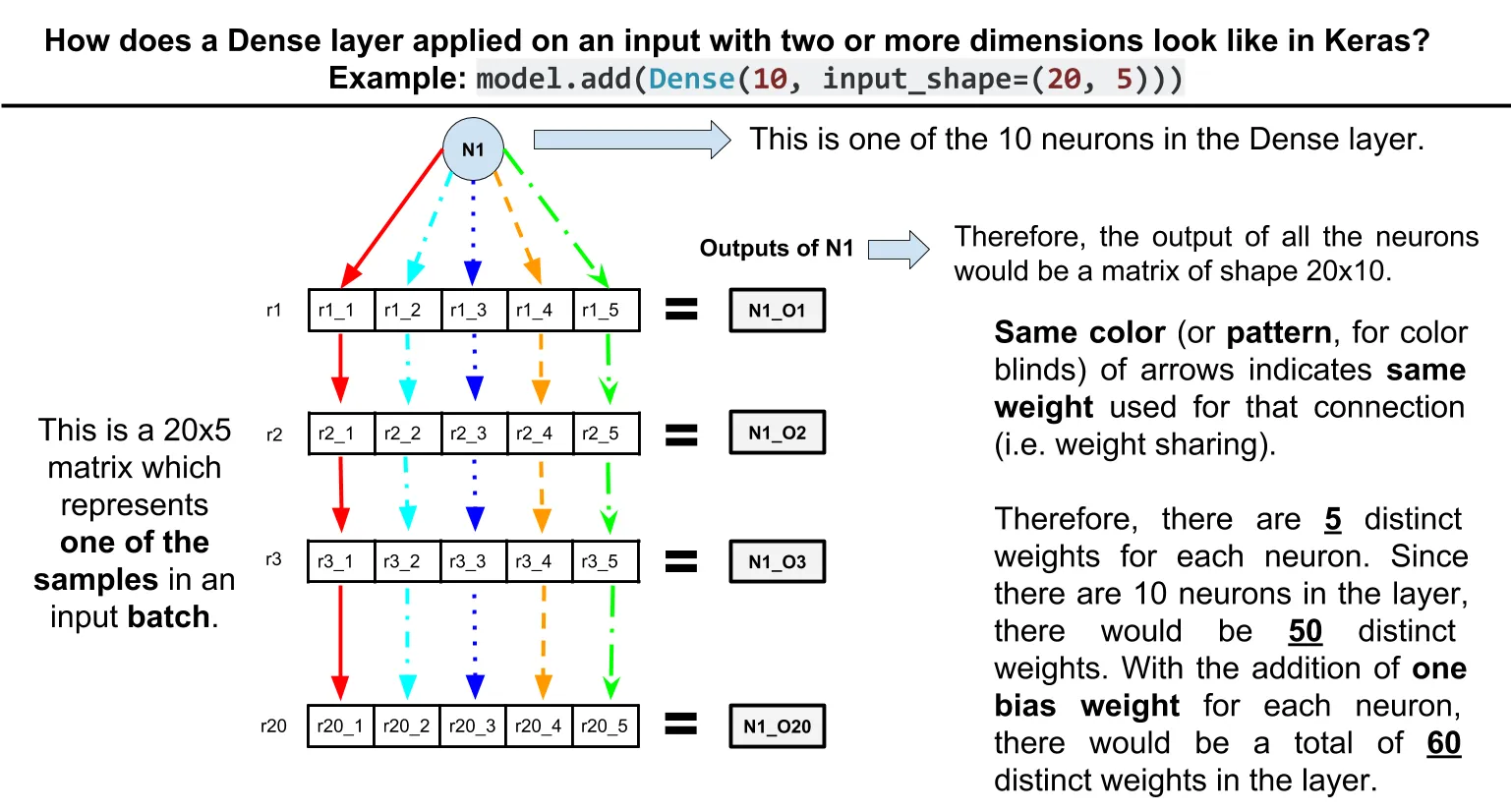
目前,与文档所述相反,Dense层被应用于输入张量的最后一个轴上:
与文档说明相反,我们实际上没有对其进行展平。它是独立地应用于最后一个轴。
换句话说,如果在形状为(n_dim1, n_dim2, ..., n_dimk)的输入张量上应用具有m个单元的Dense层,则其输出形状为(n_dim1, n_dim2, ..., m)。
另外一点注意事项:这使得TimeDistributed(Dense(...))和Dense(...)等效。
另外一条侧面说明:请注意,这会产生共享权重的效果。例如,请考虑这个玩具网络:
model = Sequential()
model.add(Dense(10, input_shape=(20, 5)))
model.summary()
模型摘要:
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_1 (Dense) (None, 20, 10) 60
=================================================================
Total params: 60
Trainable params: 60
Non-trainable params: 0
_________________________________________________________________
Dense层仅具有60个参数。如何做到的?Dense层中的每个单元都与输入中每行的5个元素使用相同权重连接,因此10 * 5 + 10(每个单元的偏置参数)= 60。