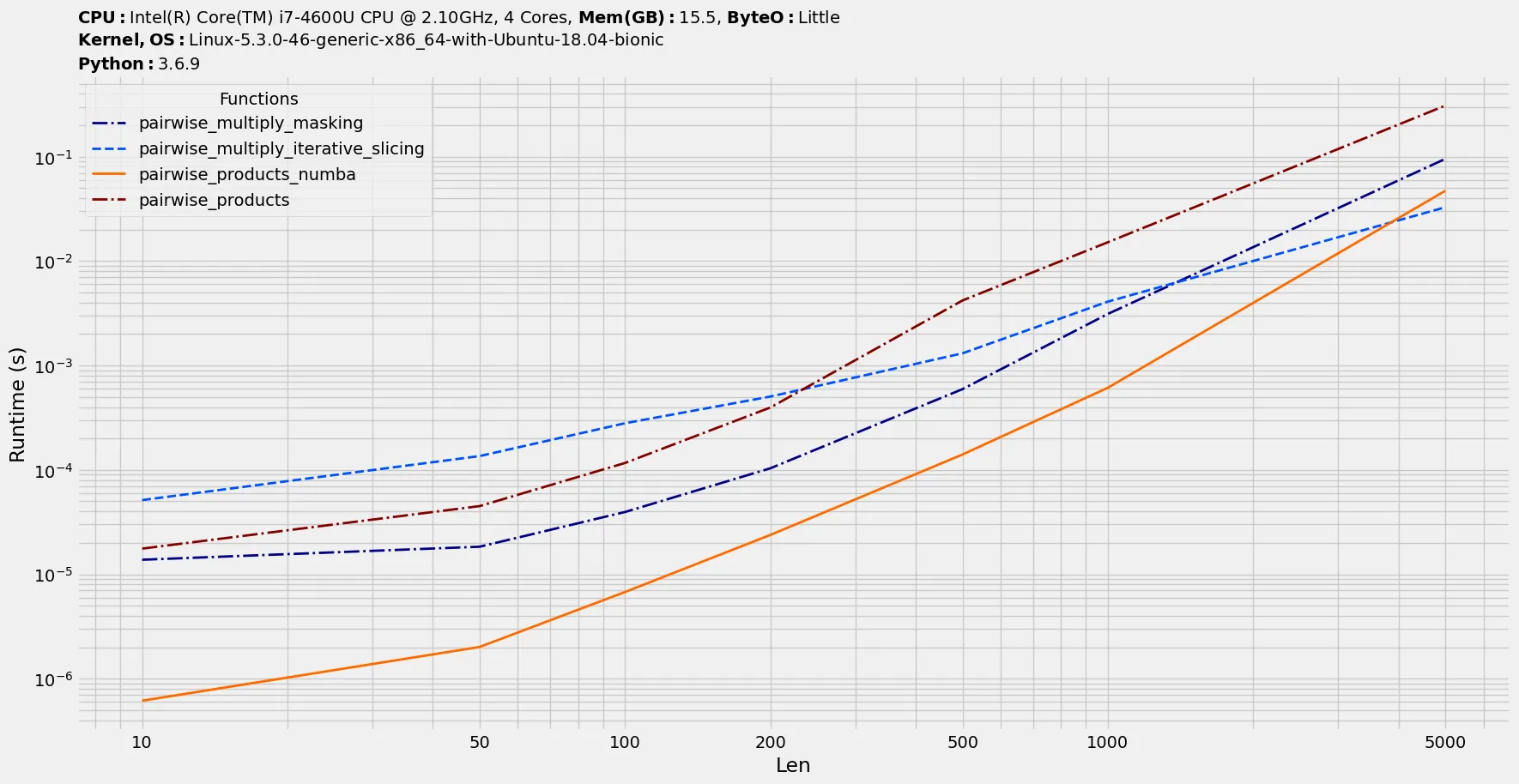
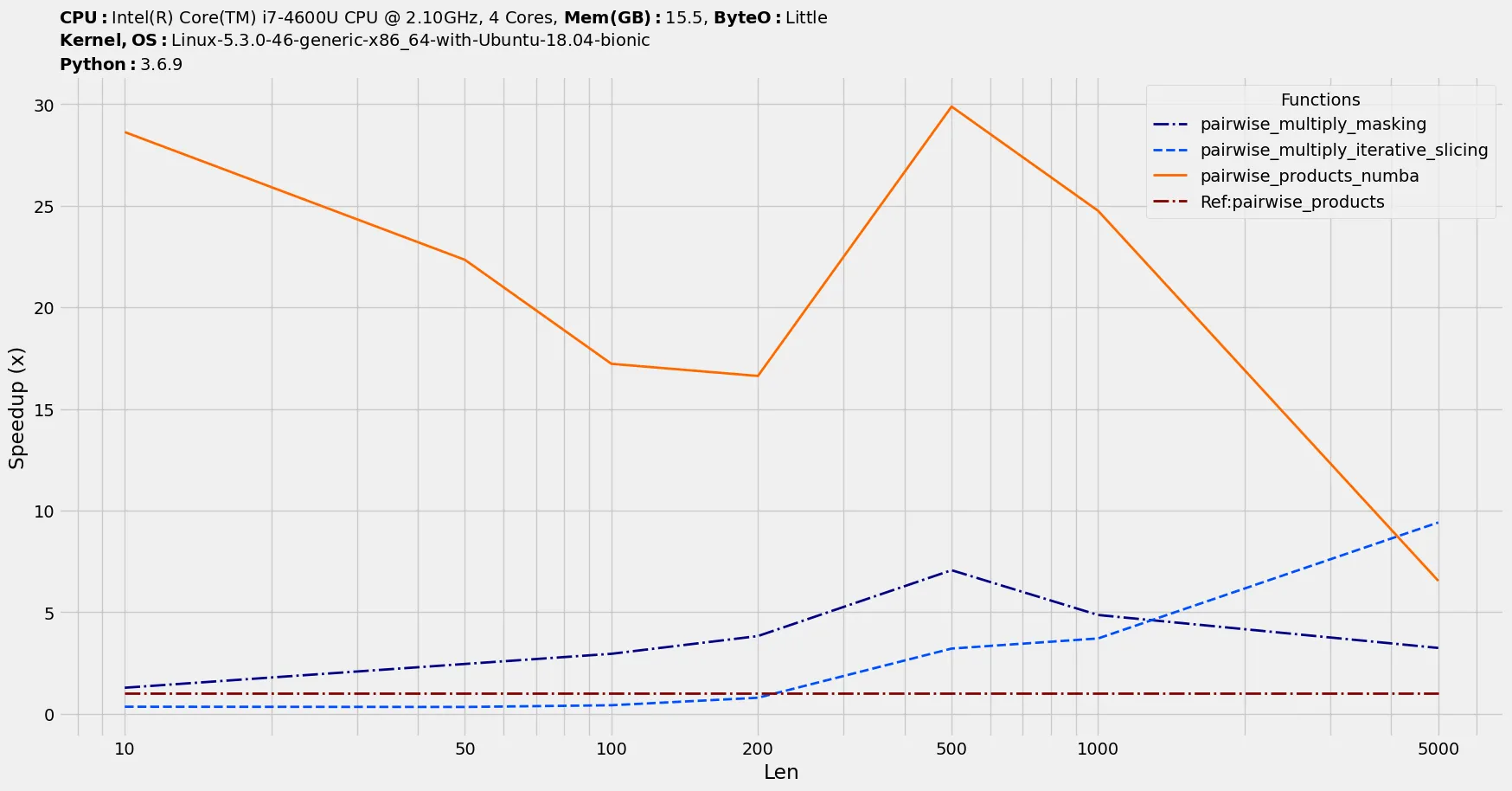
我正在寻找计算给定向量元素的所有成对乘积的“最优”方法。 如果向量大小为N ,则输出将是大小为N *(N + 1)// 2 的向量,并包含所有(i,j)对的x [i] * x [j] 值,其中 i <= j 。 计算此过程的朴素方式如下:
import numpy as np
def get_pairwise_products_naive(vec: np.ndarray):
k, size = 0, vec.size
output = np.empty(size * (size + 1) // 2)
for i in range(size):
for j in range(i, size):
output[k] = vec[i] * vec[j]
k += 1
return output
要求:
- 尽量减少内存的额外分配/使用:如果可能的话,请直接写入输出缓冲区。
- 使用向量化的NumPy例程,而不是显式循环。
- 避免额外(不必要)的计算。
我一直在尝试使用诸如outer、triu_indices和einsum等例程以及一些索引/视图技巧,但还没有找到符合上述要求的解决方案。