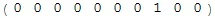希望我没有误解问题... 这里是SWI-Prolog的解决方案
:- module(subsets, [solve/0]).
:- [library(pairs),
library(aggregate)].
solve :-
problem(R, K, Subsets),
once(subset_of_maximal_number(R, K, Subsets, Subset)),
writeln(Subset).
problem(4, 2,
[[1,2,3], [1,2,3], [1,2,4], [1,3,4]]).
problem(8, 3,
[[1, 3, 4, 6], [2, 6, 7, 8], [3, 5, 6, 7], [2, 4, 6, 7], [1, 4, 5, 8],
[2, 4, 6, 8], [1, 2, 3, 8], [1, 6, 7, 8], [1, 2, 4, 7], [1, 2, 5, 7]]).
subset_of_maximal_number(R, K, Subsets, Subset) :-
flatten(Subsets, Numbers),
findall(Num-Count,
( between(1, R, Num),
aggregate_all(count, member(Num, Numbers), Count)
), NumToCount),
transpose_pairs(NumToCount, CountToNumSortedR),
reverse(CountToNumSortedR, CountToNumSorted),
length(Subset, K),
prefix(SolutionsK, CountToNumSorted),
pairs_values(SolutionsK, Subset).
测试输出:
?- solve.
[1,3]
true
[7,6,2]
true.
编辑:我认为上面的解决方案是错误的,因为返回的内容不能是任何输入的子集:这里是一个没有此问题的(注释掉的)解决方案:
:- module(subsets, [solve/0]).
:- [library(pairs),
library(aggregate),
library(ordsets)].
solve :-
problem(R, K, Subsets),
once(subset_of_maximal_number(R, K, Subsets, Subset)),
writeln(Subset).
problem(4, 2,
[[1,2,3], [1,2,3], [1,2,4], [1,3,4]]).
problem(8, 3,
[[1, 3, 4, 6], [2, 6, 7, 8], [3, 5, 6, 7], [2, 4, 6, 7], [1, 4, 5, 8],
[2, 4, 6, 8], [1, 2, 3, 8], [1, 6, 7, 8], [1, 2, 4, 7], [1, 2, 5, 7]]).
subset_of_maximal_number(R, K, Subsets, Subset) :-
flatten(Subsets, Numbers),
findall(Num-Count,
( between(1, R, Num),
aggregate_all(count, member(Num, Numbers), Count)
), NumToCount),
transpose_pairs(NumToCount, CountToNumSorted),
pairs_values(CountToNumSorted, PreferredRev),
reverse(PreferredRev, Preferred),
length(SubsetP, K),
select_k(Preferred, SubsetP),
sort(SubsetP, Subset),
once((member(S, Subsets), ord_subtract(Subset, S, []))).
select_k(_Subset, []).
select_k(Subset, [E|R]) :-
select(E, Subset, WithoutE),
select_k(WithoutE, R).
测试:
?- solve.
[1,3]
true
[2,6,7]
true.