正如@JAgustinBarrachina所指出的,接受的答案在底层使用了皮尔逊相关系数方法,这导致了一种偏见。每列的分类可能产生以下结果:
- 媒体律师 --> 0
- 学生 --> 1
- 教授 --> 2
由于皮尔逊方法计算线性相关性,它会计算每个类别之间的距离。从算法的角度来看,一个"媒体律师"与一个"教授"之间的距离(2 - 0 = 2)会比它与一个"学生"之间的距离(1 - 0 = 1)更大。然而,在这种情况下,这并不正确,因此得出的相关性将会有偏差。
从文档中还有另外两种相关性方法可用:Kendall和Spearman方法。但它们都假设类别是有序的。
例如,类别revenue : ["low", "medium", "high"]可以被视为有序。
如果一列的类别之间没有顺序关系,使用Chi²和Cramér's V方法更为合适:
import scipy.stats as ss
import pandas as pd
from pandas import DataFrame, Series
profession_and_media = DataFrame(data = {
"profession" : ["media lawyer" , "student" , "student" , "professor" , "media lawyer"] * 10,
"media" : ["print" , "online" , "print" , "online" , "online"] * 10
})
def cramers_corrected_stat(columnA: Series, columnB: Series):
""" calculate Cramers V statistic for categorial-categorial association.
uses correction from Bergsma and Wicher,
Journal of the Korean Statistical Society 42 (2013): 323-328
"""
confusion_matrix = pd.crosstab(columnA, columnB)
chi2 = ss.chi2_contingency(confusion_matrix)[0]
n = confusion_matrix.to_numpy().sum(axis=None)
phi2 = chi2/n
r,k = confusion_matrix.shape
phi2corr = max(0, phi2 - ((k-1)*(r-1))/(n-1))
rcorr = r - ((r-1)**2)/(n-1)
kcorr = k - ((k-1)**2)/(n-1)
return np.sqrt(phi2corr / min( (kcorr-1), (rcorr-1)))
def compute_category_correlation(df: DataFrame):
""" Compute the correlation between string columns of a DataFrame
"""
for column in df.columns:
df.loc[:, column] = df[column].astype('category').cat.codes
result = df.corr(method=cramers_corrected_stat)
return result.style.background_gradient(cmap='Reds')
compute_category_correlation(profession_and_media)
这给出了
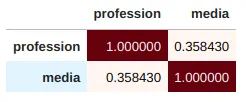
.cat.codes将您的类别从字符串表示转换为整数表示。例如,“媒体律师”将被替换为0,“学生”将被替换为1,“教授”将被替换为2。在另一列中,“打印”将被替换为0,“在线”将被替换为1。 - Corey Levinson