我正在使用Python,有一些混淆矩阵。我想通过混淆矩阵在多类分类中计算精度、召回率和F1分数。我的结果日志中不包含 y_true 和 y_pred,只包含混淆矩阵。
你能告诉我如何从混淆矩阵中获取这些得分吗?
我正在使用Python,有一些混淆矩阵。我想通过混淆矩阵在多类分类中计算精度、召回率和F1分数。我的结果日志中不包含 y_true 和 y_pred,只包含混淆矩阵。
你能告诉我如何从混淆矩阵中获取这些得分吗?
让我们考虑 MNIST 数据分类的情况(10 类),对于一个测试集包含 10,000 个样本,我们得到了以下混淆矩阵 cm(Numpy 数组):
array([[ 963, 0, 0, 1, 0, 2, 11, 1, 2, 0],
[ 0, 1119, 3, 2, 1, 0, 4, 1, 4, 1],
[ 12, 3, 972, 9, 6, 0, 6, 9, 13, 2],
[ 0, 0, 8, 975, 0, 2, 2, 10, 10, 3],
[ 0, 2, 3, 0, 953, 0, 11, 2, 3, 8],
[ 8, 1, 0, 21, 2, 818, 17, 2, 15, 8],
[ 9, 3, 1, 1, 4, 2, 938, 0, 0, 0],
[ 2, 7, 19, 2, 2, 0, 0, 975, 2, 19],
[ 8, 5, 4, 8, 6, 4, 14, 11, 906, 8],
[ 11, 7, 1, 12, 16, 1, 1, 6, 5, 949]])
# numpy should have already been imported as np
TP = np.diag(cm)
TP
# array([ 963, 1119, 972, 975, 953, 818, 938, 975, 906, 949])
假阳性是各列的总和减去对角线元素(即TP元素):
FP = np.sum(cm, axis=0) - TP
FP
# array([50, 28, 39, 56, 37, 11, 66, 42, 54, 49])
FN = np.sum(cm, axis=1) - TP
FN
# array([17, 16, 60, 35, 29, 74, 20, 53, 68, 60])
现在,真阴性(True Negatives)有点棘手。首先让我们考虑什么是真阴性,以类别0为例:它意味着所有被正确识别出不属于0的样本。因此,我们应该做的是从混淆矩阵中删除相应的行和列,然后将所有剩余元素相加。
num_classes = 10
TN = []
for i in range(num_classes):
temp = np.delete(cm, i, 0) # delete ith row
temp = np.delete(temp, i, 1) # delete ith column
TN.append(sum(sum(temp)))
TN
# [8970, 8837, 8929, 8934, 8981, 9097, 8976, 8930, 8972, 8942]
让我们进行一个合理性检查:对于每个类别,TP、FP、FN和TN的总和必须等于我们测试集的大小(这里是10,000):让我们确认这确实是事实:
l = 10000
for i in range(num_classes):
print(TP[i] + FP[i] + FN[i] + TN[i] == l)
结果是
True
True
True
True
True
True
True
True
True
True
计算了这些量之后,现在很容易获得每个类别的精确度和召回率:
precision = TP/(TP+FP)
recall = TP/(TP+FN)
对于这个例子而言,它们是
precision
# array([ 0.95064166, 0.97558849, 0.96142433, 0.9456838 , 0.96262626,
# 0.986731 , 0.93426295, 0.95870206, 0.94375 , 0.9509018])
recall
# array([ 0.98265306, 0.98590308, 0.94186047, 0.96534653, 0.97046843,
# 0.91704036, 0.97912317, 0.94844358, 0.9301848 , 0.94053518])
同样地,我们可以计算出相关的量,如特异度(记住敏感度是召回率的同义词):
specificity = TN/(TN+FP)
我们示例的结果:
specificity
# array([0.99445676, 0.99684151, 0.9956512 , 0.99377086, 0.99589709,
# 0.99879227, 0.99270073, 0.99531877, 0.99401728, 0.99455011])
现在您应该能够针对您混淆矩阵的任何大小计算这些量。
TN = np.repeat(np.sum(cm), 3) - TP - FP - FN - dana nadlercmat = [[ 5, 7],
[25, 37]]
可以制作以下简单函数:
def myscores(smat):
tp = smat[0][0]
fp = smat[0][1]
fn = smat[1][0]
tn = smat[1][1]
return tp/(tp+fp), tp/(tp+fn)
测试:
print("precision and recall:", myscores(cmat))
输出:
precision and recall: (0.4166666666666667, 0.16666666666666666)
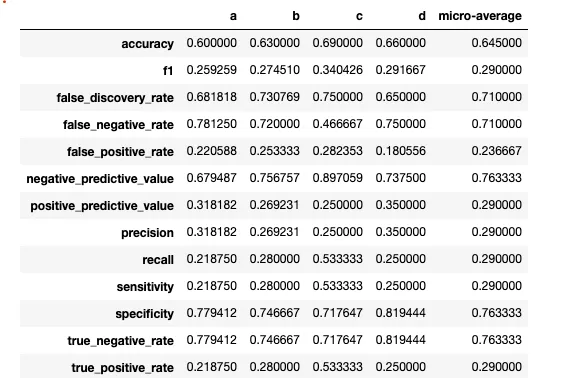
有一个名为 'disarray' 的软件包。
那么,如果我有四个类:
import numpy as np
a = np.random.randint(0,4,[100])
b = np.random.randint(0,4,[100])
我可以使用numpy来计算13个矩阵:
import disarray
# Instantiate the confusion matrix DataFrame with index and columns
cm = confusion_matrix(a,b)
df = pd.DataFrame(cm, index= ['a','b','c','d'], columns=['a','b','c','d'])
df.da.export_metrics()
这提供了: