您可以使用计数器来计算,然后
uniqify原始列表以维护顺序并添加计数。
假设:
>>> dates=[datetime.date(2017, 3, 9), datetime.date(2017, 3, 10), datetime.date(2017, 3, 10), datetime.date(2017, 3, 11)]
您可以执行以下操作:
from collections import Counter
cnts=Counter(dates)
seen=set()
>>> [(e, cnts[e]) for e in dates if not (e in seen or seen.add(e))]
[(datetime.date(2017, 3, 9), 1), (datetime.date(2017, 3, 10), 2), (datetime.date(2017, 3, 11), 1)]
更新
您还可以使用键函数获取原始列表中日期(X)的第一个条目的索引,将计数器排序回原始列表的顺序:
sorted([(k,v) for k,v in Counter(dates).items()], key=lambda t: dates.index(t[0]))
这与您的列表排序程度有关,排序程度越高速度越快...
有人提到了timeit!
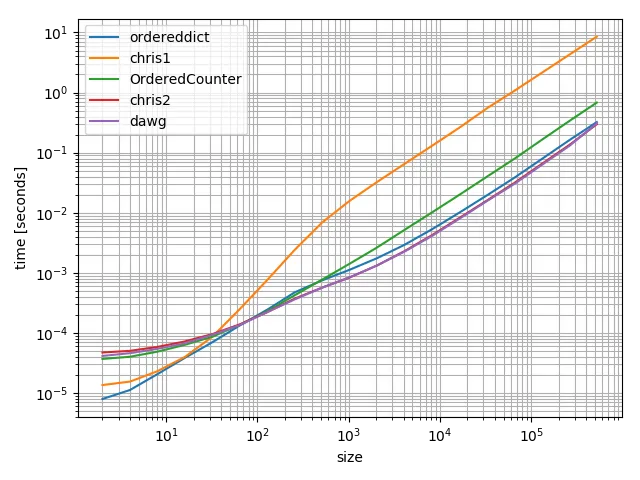
以下是一个更大的例子(400,000个日期)的计时:
from __future__ import print_function
import datetime
from collections import Counter
from collections import OrderedDict
def dawg1(dates):
seen=set()
cnts=Counter(dates)
return [(e, cnts[e]) for e in dates if not (e in seen or seen.add(e))]
def od_(dates):
odct = OrderedDict()
for item in dates:
try:
odct[item] += 1
except KeyError:
odct[item] = 1
return odct
def lc_(lst):
return [(item,lst.count(item)) for item in list(OrderedDict.fromkeys(lst))]
def dawg2(dates):
return sorted([(k,v) for k,v in Counter(dates).items()], key=lambda t: dates.index(t[0]))
if __name__=='__main__':
import timeit
dates=[datetime.date(2017, 3, 9), datetime.date(2017, 3, 10), datetime.date(2017, 3, 10), datetime.date(2017, 3, 11)]*100000
for f in (dawg, od_, lc_,sort_):
print(" {:^10s}{:.4f} secs {}".format(f.__name__, timeit.timeit("f(dates)", setup="from __main__ import f, dates", number=100),f(dates)))
Python 2.7 的输出结果:
dawg1 10.7253 secs [(datetime.date(2017, 3, 9), 100000), (datetime.date(2017, 3, 10), 200000), (datetime.date(2017, 3, 11), 100000)]
od_ 21.8186 secs OrderedDict([(datetime.date(2017, 3, 9), 100000), (datetime.date(2017, 3, 10), 200000), (datetime.date(2017, 3, 11), 100000)])
lc_ 17.0879 secs [(datetime.date(2017, 3, 9), 100000), (datetime.date(2017, 3, 10), 200000), (datetime.date(2017, 3, 11), 100000)]
dawg2 8.6058 secs [(datetime.date(2017, 3, 9), 100000), (datetime.date(2017, 3, 10), 200000), (datetime.date(2017, 3, 11), 100000)]0000)]
PyPy:
dawg1 7.1483 secs [(datetime.date(2017, 3, 9), 100000), (datetime.date(2017, 3, 10), 200000), (datetime.date(2017, 3, 11), 100000)]
od_ 4.7551 secs OrderedDict([(datetime.date(2017, 3, 9), 100000), (datetime.date(2017, 3, 10), 200000), (datetime.date(2017, 3, 11), 100000)])
lc_ 27.8438 secs [(datetime.date(2017, 3, 9), 100000), (datetime.date(2017, 3, 10), 200000), (datetime.date(2017, 3, 11), 100000)]
dawg2 4.7673 secs [(datetime.date(2017, 3, 9), 100000), (datetime.date(2017, 3, 10), 200000), (datetime.date(2017, 3, 11), 100000)]
Python 3.6:
dawg1 3.4944 secs [(datetime.date(2017, 3, 9), 100000), (datetime.date(2017, 3, 10), 200000), (datetime.date(2017, 3, 11), 100000)]
od_ 4.6541 secs OrderedDict([(datetime.date(2017, 3, 9), 100000), (datetime.date(2017, 3, 10), 200000), (datetime.date(2017, 3, 11), 100000)])
lc_ 2.7440 secs [(datetime.date(2017, 3, 9), 100000), (datetime.date(2017, 3, 10), 200000), (datetime.date(2017, 3, 11), 100000)]
dawg2 2.1330 secs [(datetime.date(2017, 3, 9), 100000), (datetime.date(2017, 3, 10), 200000), (datetime.date(2017, 3, 11), 100000)]
最好的。