如何从列表中删除重复项,同时保留顺序?使用集合来删除重复项会破坏原始顺序。是否有内置函数或Python惯用语?
31个回答
897
以下是一些选择:http://www.peterbe.com/plog/uniqifiers-benchmark
最快的选择:
def f7(seq):
seen = set()
seen_add = seen.add
return [x for x in seq if not (x in seen or seen_add(x))]
为什么将
seen.add赋值给seen_add而不是直接调用seen.add?Python是一种动态语言,每次迭代解析seen.add的成本比解析局部变量更高。 seen.add可能在迭代之间发生了改变,运行时无法排除这种可能性。为了安全起见,它必须每次都检查对象。
如果您计划在相同数据集上经常使用此函数,则最好使用有序集:http://code.activestate.com/recipes/528878/
每个操作的O(1)插入、删除和成员检查。(小额附注:
seen.add()始终返回None,因此上面的or只是尝试进行设置更新的方式,并不是逻辑测试的必要部分。)- MizardX
28
719
最佳解决方案因Python版本和环境限制而异:
Python 3.7+(以及大多数支持3.6的解释器,作为实现细节):
首次引入于PyPy 2.5.0,并在CPython 3.6中作为实现细节采用,然后在Python 3.7中成为语言保证,普通的dict是按插入顺序排序的,甚至比(同样是CPython 3.5的C实现)collections.OrderedDict更高效。因此,迄今为止,最快速的解决方案也是最简单的:
像
只需要导入一个简单的库,不需要任何技巧。
该模块正在适应itertools的配方
但与itertools的方法不同,它支持非可哈希项(性能有所损失;如果iterable中的所有元素都是非可哈希的,则算法变为O(n²),而如果它们都是可哈希的,则为O(n))。
重要提示:与这里的所有其他解决方案不同,unique_everseen可以懒惰地使用;峰值内存使用量将相同(最终,底层集合的大小会增长到相同的大小),但如果您不将结果转换为列表,只需迭代它,您将能够在找到唯一项之前处理它们,而不必等待整个输入被去重后再处理第一个唯一项。
Python 3.4及更早版本,如果性能至关重要且无法使用第三方模块,您有两个选择:
Python 3.7+(以及大多数支持3.6的解释器,作为实现细节):
首次引入于PyPy 2.5.0,并在CPython 3.6中作为实现细节采用,然后在Python 3.7中成为语言保证,普通的dict是按插入顺序排序的,甚至比(同样是CPython 3.5的C实现)collections.OrderedDict更高效。因此,迄今为止,最快速的解决方案也是最简单的:
>>> items = [1, 2, 0, 1, 3, 2]
>>> list(dict.fromkeys(items)) # Or [*dict.fromkeys(items)] if you prefer
[1, 2, 0, 3]
像
list(set(items))这样的操作将所有工作都推到了C层(在CPython上),但由于dict是按插入顺序排序的,所以dict.fromkeys不会丢失顺序。它比list(set(items))慢(通常需要50-100%的时间),但比任何其他保持顺序的解决方案要快得多(大约比涉及在列表推导中使用set的hack方法快一半)。
重要提示:来自more_itertools的unique_everseen解决方案(见下文)在惰性和对非可哈希输入项的支持方面具有独特的优势;如果您需要这些功能,它是唯一可行的解决方案。
Python 3.5(以及所有旧版本,如果性能不是关键)
根据Raymond的指出,在CPython 3.5中,使用C语言实现的`OrderedDict`,丑陋的列表推导式技巧比`OrderedDict.fromkeys`慢(除非你实际上需要最后的列表 - 即使是这样也只有在输入非常短的情况下才是如此)。因此,对于CPython 3.5来说,在性能和可读性上,最好的解决方案是使用等效于3.6+中普通`dict`的`OrderedDict`。>>> from collections import OrderedDict
>>> items = [1, 2, 0, 1, 3, 2]
>>> list(OrderedDict.fromkeys(items))
[1, 2, 0, 3]
在CPython 3.4及更早版本中,这将比其他一些解决方案慢,所以如果性能分析显示你需要更好的解决方案,请继续阅读。
对于Python 3.4及更早版本,如果性能至关重要且可以接受第三方模块
正如@abarnert所指出的,more_itertools库(pip install more_itertools)包含一个unique_everseen函数,该函数被设计用于在列表推导式中不进行任何难以理解的(not seen.add)变异。这也是最快的解决方案:
>>> from more_itertools import unique_everseen
>>> items = [1, 2, 0, 1, 3, 2]
>>> list(unique_everseen(items))
[1, 2, 0, 3]
只需要导入一个简单的库,不需要任何技巧。
该模块正在适应itertools的配方
unique_everseen,它看起来像这样:def unique_everseen(iterable, key=None):
"List unique elements, preserving order. Remember all elements ever seen."
# unique_everseen('AAAABBBCCDAABBB') --> A B C D
# unique_everseen('ABBCcAD', str.lower) --> A B C D
seen = set()
seen_add = seen.add
if key is None:
for element in filterfalse(seen.__contains__, iterable):
seen_add(element)
yield element
else:
for element in iterable:
k = key(element)
if k not in seen:
seen_add(k)
yield element
但与itertools的方法不同,它支持非可哈希项(性能有所损失;如果iterable中的所有元素都是非可哈希的,则算法变为O(n²),而如果它们都是可哈希的,则为O(n))。
重要提示:与这里的所有其他解决方案不同,unique_everseen可以懒惰地使用;峰值内存使用量将相同(最终,底层集合的大小会增长到相同的大小),但如果您不将结果转换为列表,只需迭代它,您将能够在找到唯一项之前处理它们,而不必等待整个输入被去重后再处理第一个唯一项。
Python 3.4及更早版本,如果性能至关重要且无法使用第三方模块,您有两个选择:
将the
unique_everseenrecipe复制并粘贴到您的代码中,并按照上面的more_itertools示例使用它。使用丑陋的技巧来允许单个列表推导式同时检查和更新一个
set以跟踪已经出现的元素:seen = set() [x for x in seq if x not in seen and not seen.add(x)]这样做的代价是依赖于这个丑陋的技巧:
not seen.add(x)它依赖于
set.add是一个始终返回None的原地方法,所以not None求值为True。
O(n)(除了在非可哈希项的可迭代对象上调用unique_everseen,其时间复杂度为O(n²),而其他解决方案会立即出现TypeError错误)。因此,当它们不是最热门的代码路径时,所有解决方案的性能都足够好。选择使用哪个解决方案取决于您可以依赖的语言规范/解释器/第三方模块的版本,性能是否至关重要(不要假设它是;通常并非如此),以及最重要的是可读性(因为如果稍后维护此代码的人处于杀气腾腾的心情中,您聪明的微小优化可能不值得)。- jamylak
15
5为了获取键而将其转换为某种自定义字典?只是另一种拐杖。 - Nakilon
8@Nakilon,我并不认为它是一个累赘。从那个角度来看,它并没有暴露任何可变状态,因此非常干净。在内部,Python集合使用dict() 实现(https://dev59.com/o2865IYBdhLWcg3wLbar),所以基本上你只是在做解释器本来就会做的事情。 - Imran
1@EMS 这并不能保持顺序。你可以直接使用
seen = set(seq)。 - flornquake1@CommuSoft 我同意,尽管在实践中由于极其不太可能的最坏情况,几乎总是O(n)。 - jamylak
1@MichaelGofron 这是一个外部库,所以您需要安装它。例如:
pip install more_itertools。 - jamylak显示剩余10条评论
161
在CPython 3.6+ (以及所有其他从Python 3.7+ 开始的Python实现)中,字典是有序的,因此在保留原始顺序的同时从可迭代对象中删除重复项的方法是:
>>> list(dict.fromkeys('abracadabra'))
['a', 'b', 'r', 'c', 'd']
在Python 3.5及以下版本(包括Python 2.7),请使用OrderedDict。我的测试表明,对于Python 3.5来说,这是各种方法中最快且最短的解决方案(当它获得C实现之后;在3.5之前,它仍然是最清晰的解决方案,尽管不是最快的)。
>>> from collections import OrderedDict
>>> list(OrderedDict.fromkeys('abracadabra'))
['a', 'b', 'r', 'c', 'd']
- Raymond Hettinger
6
9唯一需要注意的是可迭代对象 "elements" 必须是可哈希的 - 如果能够处理任意元素类型的可迭代对象(如列表嵌套列表),那就更好了。 - Mr_and_Mrs_D
字典的插入顺序迭代提供了比去重更多用例的功能。例如,科学分析依赖于可重复计算,而非确定性字典迭代不支持此功能。可重复性是计算科学建模中的一个主要目标,因此我们欢迎这个新功能。
虽然我知道使用确定性字典构建是微不足道的,但高性能、确定性的
set() 将帮助更多的初学者开发可重复的代码。 - Arthur使用
[*dict.fromkeys('abracadabra')](解包)代替调用函数 list(...) 怎么样?在我的测试中,这种方法更快,尽管只有非常小的差异可以被检测到。所以我不确定这是否只是巧合。 - colidyre1@colidyre 是的,那样做可以。小的速度差异可能是由于运算符不必查找内置函数造成的。还需要考虑清晰度的问题。 - Raymond Hettinger
2@RaymondHettinger:查找成本很小(在3.8的
LOAD_GLOBAL中变得更小);主要优点是避免构造函数路径(需要构造tuple以获得args,将NULL指针作为kwargs dict传递,然后分别调用两个几乎为空的__new__和__init__,后者必须通过一般化的参数解析代码,以传递0-1个位置参数)。但从3.9开始,list()通过向量调用协议绕过了大部分这些操作,从而将增量利益从60-70纳秒(3.8.5)降低到20-30纳秒(3.10.0)在我的机器上。 - ShadowRanger1@Mr_and_Mrs_D,如果没有哈希,就不可能在O(n)的时间内去重元素。对于任意元素的去重都需要O(n^2)的时间复杂度。 - Paul Draper
44
不想再多说废话(因为这个问题很老,已经有很多好的回答了),但是我有一个使用pandas解决方案,它在许多情况下非常快速且易于使用。
import pandas as pd
my_list = [0, 1, 2, 3, 4, 1, 2, 3, 5]
>>> pd.Series(my_list).drop_duplicates().tolist()
# Output:
# [0, 1, 2, 3, 4, 5]
- Alexander
1
1有用,但不保留顺序。
more_itertools.unique_everseen 可以做到。 - baxx34
sequence = ['1', '2', '3', '3', '6', '4', '5', '6']
unique = []
[unique.append(item) for item in sequence if item not in unique]
唯一的 → ['1', '2', '3', '6', '4', '5']
- dansalmo
3
31值得注意的是,这个程序的时间复杂度是
n^2。 - loopbackbee31啊,有两处问题:第一,在成员检测中使用列表(速度慢,每次测试的时间复杂度为O(N));其次,在列表推导式中使用了副作用(在此过程中建立了另一个由“None”引用组成的列表!)。 - Martijn Pieters
3我同意@MartijnPieters的观点,没有任何理由使用具有副作用的列表推导式。只需改用
for循环即可。 - jamylak29
from itertools import groupby
[key for key, _ in groupby(sortedList)]
列表甚至不需要被排序,足够的条件是相等的值被分组在一起。 编辑:我假设"保留顺序"意味着列表实际上是有序的。如果不是这种情况,那么MizardX的解决方案就是正确的。 社区编辑:这是将"重复的连续元素压缩成一个元素"最优雅的方法。
- Rafał Dowgird
11
1但这样做无法保持顺序! - unbeknown
1这有问题,因为我不能保证相等的值在不循环遍历列表的情况下分组在一起,而到那时我可能已经修剪了重复项。 - Josh Glover
1也许输入列表的规范有点不清楚。这些值甚至不需要被分组在一起:[2, 1, 3, 1]。那么哪些值应该保留,哪些应该删除? - unbeknown
在这种情况下,下划线
_ 是做什么用的? - igorkf1@igorkf 忽略成对元素的第二个元素。 - Rafał Dowgird
显示剩余6条评论
26
我认为如果你想要维持秩序,
你可以尝试这个方法:
list1 = ['b','c','d','b','c','a','a']
list2 = list(set(list1))
list2.sort(key=list1.index)
print list2
或者你也可以这样做:
list1 = ['b','c','d','b','c','a','a']
list2 = sorted(set(list1),key=list1.index)
print list2
你也可以这样做:
list1 = ['b','c','d','b','c','a','a']
list2 = []
for i in list1:
if not i in list2:
list2.append(i)`
print list2
它还可以写成这样:
list1 = ['b','c','d','b','c','a','a']
list2 = []
[list2.append(i) for i in list1 if not i in list2]
print list2
- shamrock
2
4前两个回答假设列表的顺序可以使用排序函数重建,但情况可能并非如此。 - Richard
6大多数答案都集中在性能方面。对于那些不够大而需要担心性能的列表,sorted(set(list1),key=list1.index) 是我见过的最好的方法。没有额外的导入、函数或变量,它相当简单易读。 - Derek Veit
16
只是想添加另一个(非常高效)来自外部模块的此类功能的实现1:iteration_utilities.unique_everseen:
>>> from iteration_utilities import unique_everseen
>>> lst = [1,1,1,2,3,2,2,2,1,3,4]
>>> list(unique_everseen(lst))
[1, 2, 3, 4]
时间
我进行了一些时间测试(使用Python 3.6),结果显示它比我测试过的所有其他替代方法都要快,包括OrderedDict.fromkeys、f7和more_itertools.unique_everseen。
%matplotlib notebook
from iteration_utilities import unique_everseen
from collections import OrderedDict
from more_itertools import unique_everseen as mi_unique_everseen
def f7(seq):
seen = set()
seen_add = seen.add
return [x for x in seq if not (x in seen or seen_add(x))]
def iteration_utilities_unique_everseen(seq):
return list(unique_everseen(seq))
def more_itertools_unique_everseen(seq):
return list(mi_unique_everseen(seq))
def odict(seq):
return list(OrderedDict.fromkeys(seq))
from simple_benchmark import benchmark
b = benchmark([f7, iteration_utilities_unique_everseen, more_itertools_unique_everseen, odict],
{2**i: list(range(2**i)) for i in range(1, 20)},
'list size (no duplicates)')
b.plot()
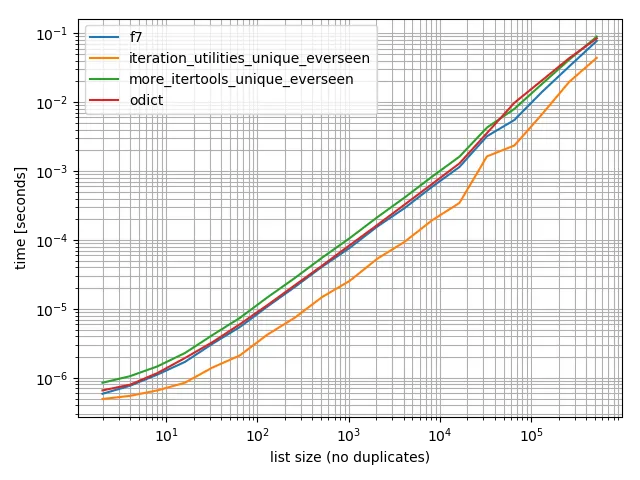
为了确保,我也进行了更多重复测试,以检查是否有差异:
import random
b = benchmark([f7, iteration_utilities_unique_everseen, more_itertools_unique_everseen, odict],
{2**i: [random.randint(0, 2**(i-1)) for _ in range(2**i)] for i in range(1, 20)},
'list size (lots of duplicates)')
b.plot()
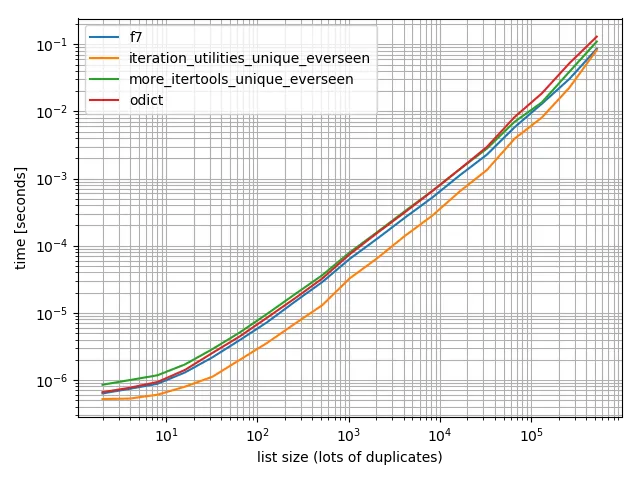
还有一个只包含一个值的:
b = benchmark([f7, iteration_utilities_unique_everseen, more_itertools_unique_everseen, odict],
{2**i: [1]*(2**i) for i in range(1, 20)},
'list size (only duplicates)')
b.plot()
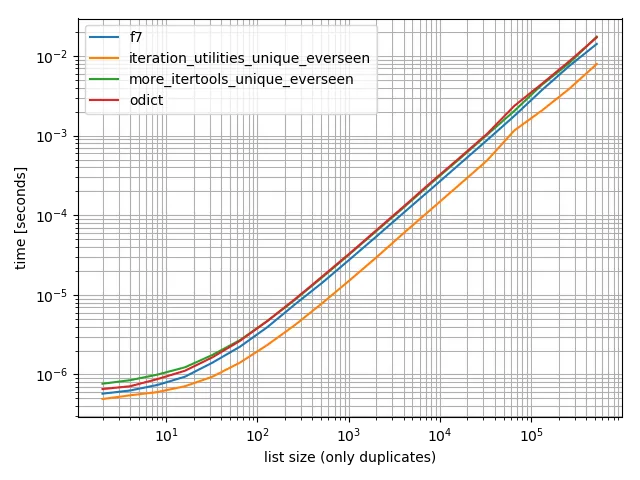
在所有这些情况中,iteration_utilities.unique_everseen 函数是最快的(在我的电脑上)。
这个 iteration_utilities.unique_everseen 函数还可以处理输入中的不可哈希值(但其性能为 O(n*n) 而不是当值是可哈希时的 O(n) 性能)。
>>> lst = [{1}, {1}, {2}, {1}, {3}]
>>> list(unique_everseen(lst))
[{1}, {2}, {3}]
1 声明:我是该软件包的作者。
- MSeifert
7
我不理解这行代码的必要性:
seen_add = seen.add -- 这对基准测试有必要吗? - Alex请问能否在您的图表中添加
dict.fromkeys()方法? - user3064538这个iteration_utilities.unique_everseen函数还可以处理输入中的不可哈希值 -- 是的,这非常重要。如果你有一个字典列表,其中包含了多层嵌套的字典等等,那么即使在小规模情况下,这也是唯一的解决方法。 - Roko Mijic
为什么要使用这个而不是
more_itertools.unique_everseen?我不确定它们为什么有相同的名称。 - baxx@baxx 如果你已经有了
more-itertools,那么使用来自 more-itertools 的函数可能更好、更容易(少依赖)。如果你需要获得最佳性能,那么 iteration_uitilities 在写作时(或至少在写作时)显然更快,如果我正确地阅读图表的话,似乎快了约2倍。如果你不太关心性能:随便用吧。例如,在其他答案中有一些实现非常简短,可能很容易复制和粘贴 :) - MSeifert显示剩余2条评论
11
针对另一个非常老的问题的另一个非常晚的回答:
itertools recipes函数提供了一个使用seen集合技术完成此操作的功能,但是:
- 处理标准的
key函数。 - 不使用任何不当的技巧。
- 通过预先绑定
seen.add来优化循环,而不是N次查找。(f7也这样做,但某些版本不支持。) - 通过使用
ifilterfalse来优化循环,因此您只需在Python中循环遍历唯一元素,而不是所有元素。(当然,您仍需要在ifilterfalse内部迭代所有元素,但这是在C中进行的,速度更快。)
这个方法比 f7 快吗?这取决于你的数据,所以你需要测试一下。如果你想得到一个列表,f7 使用了一个列表推导式,在这里没有办法做到。 (你可以直接使用 append 而不是 yield,或者将生成器传递给 list 函数,但两者都无法像列表推导式中的 LIST_APPEND 一样快。)无论如何,通常,挤出几微秒并不像拥有一个易于理解、可重用、已编写的函数那样重要,当你想要装饰时也不需要 DSU。
与所有食谱一样,它也可以在 more-iterools 中找到。
如果你只想要没有 key 的情况,你可以简化它:
def unique(iterable):
seen = set()
seen_add = seen.add
for element in itertools.ifilterfalse(seen.__contains__, iterable):
seen_add(element)
yield element
- abarnert
1
我完全忽略了
more-itertools,这显然是最好的答案。一个简单的from more_itertools import unique_everseen list(unique_everseen(items))比我的方法快得多,也比被接受的答案好得多,我认为下载这个库是值得的。我将把我的答案添加到社区wiki中,并加入这个方法。 - jamylak网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接
seen_add是一项改进,但时间可能会受到系统资源的影响。很想看到完整的计时结果。 - jamylakseen_add = seen.add和没有使用它只会增加1%的速度,这几乎没有什么意义。 - sleblanc