我正在寻找一种高效、均匀分布的伪随机数生成器,它可以为平面上任意整数点(以坐标 x 和 y 作为函数输入)生成一个随机整数。
int rand(int x, int y)
它必须在每次输入相同坐标时提供相同的随机数。
您是否了解可以用于此类问题以及更高维度中的算法?
我已经尝试使用普通的伪随机数生成器,例如LFSR,并将x、y坐标合并在一起作为种子值。就像这样:
int seed = x << 16 | (y & 0xFFFF)
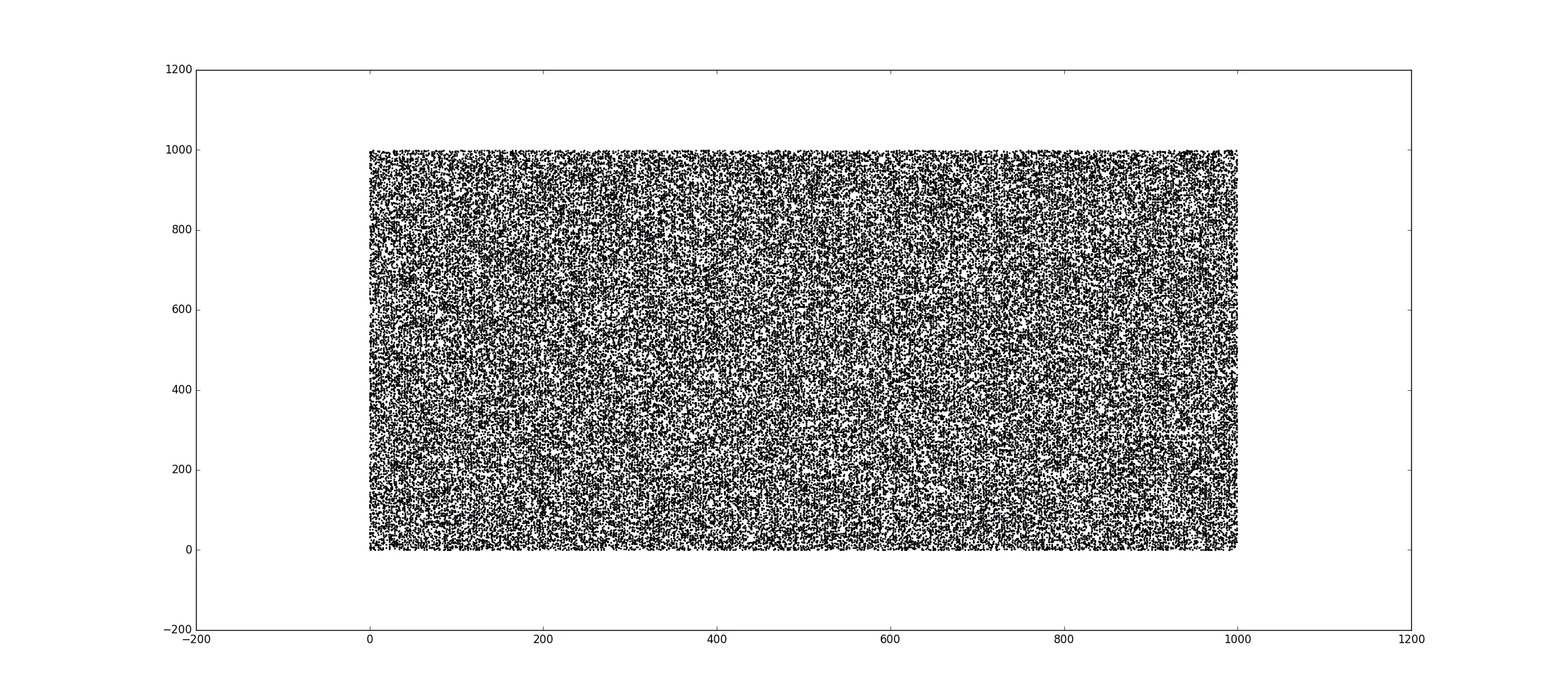
这种方法的明显问题是种子不会被多次迭代,而是为每个x、y点重新初始化。如果您可视化结果,这将导致非常丑陋的非随机模式。
我已经知道了一种方法,它使用某些大小为256的洗牌置换表,并从中获取一个随机整数。
int r = P[x + P[y & 255] & 255];
但我不想使用这种方法,因为它的范围非常有限,受限制的时间长度和高内存消耗。
感谢任何有用的建议!