我是R语言的新手,我试图做一些我认为应该非常简单的事情,但是在线上的代码并没有帮助到我。
data <- structure(list(Group = c(1, 1, 1, 1, 2, 2, 2, 2, 3, 3, 3, 3),
Time = c(1, 1, 2, 2, 1, 1, 2, 2, 1, 1, 2, 2), mean_PctPasses = c(68.26,
60.2666666666667, 62.05, 66.3833333333333, 59.7333333333333,
69.7714285714286, 57.1888888888889, 63.8875, 61.1833333333333,
59.775, 66.2666666666667, 62.12), mean_AvgPassing = c(7.3,
7.01111111111111, 6.35, 9.26666666666667, 6.68333333333333,
8.78571428571429, 5.87777777777778, 8.3125, 7.63333333333333,
7.7, 8.38333333333334, 6.89), mean_AvgRush = c(0.3, -0.3,
3.5, 0.75, 5, 1.47142857142857, 5.71111111111111, 3.3875,
2.74, 6.6, 4.5, 5), mean_Int = c(0.2, 0.777777777777778,
0.25, 0.5, 1.5, 0.857142857142857, 0.777777777777778, 0.75,
0.666666666666667, 0.75, 0.833333333333333, 1.1), mean_Rate = c(99.3,
88.5222222222222, 80.5, 106.45, 77.2333333333333, 102.885714285714,
76.8888888888889, 100.075, 92.1166666666667, 78.55, 98.05,
79.56)), class = c("tbl_df", "tbl", "data.frame"), row.names = c(NA,
-12L), .Names = c("Group", "Time", "mean_PctPasses", "mean_AvgPassing",
"mean_AvgRush", "mean_Int", "mean_Rate"))
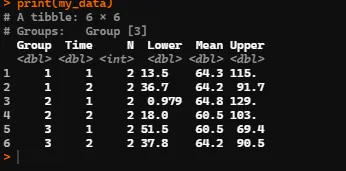
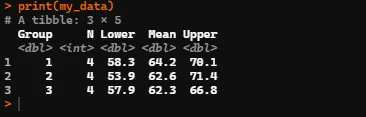
使用这个数据集,我有两个分组变量"Group"和"Time"。我想以表格的形式获得每个组合的均值和置信区间,涉及的变量是mean_PctPasses到mean_Rate,并将结果保存在表格中。我需要它以表格的形式呈现,因为我稍后会在plotly中引用它。在SPSS中完成这个任务非常容易。
我尝试了几个函数,下面是每个函数的问题。
library(rcompanion)
ci.mean(mean_PctPasses~Group+Time, data = data)
library(DescTools)
MeanCI(data$mean_PctPasses)
library(Rmisc)
CI(data$mean_PctPasses, ci=0.95)
MeanCI、ci.mean和CI不允许列出多个变量,并且保存为表格(仅在控制台中显示)。
by(data = data, data$Group, FUN = stat.desc)
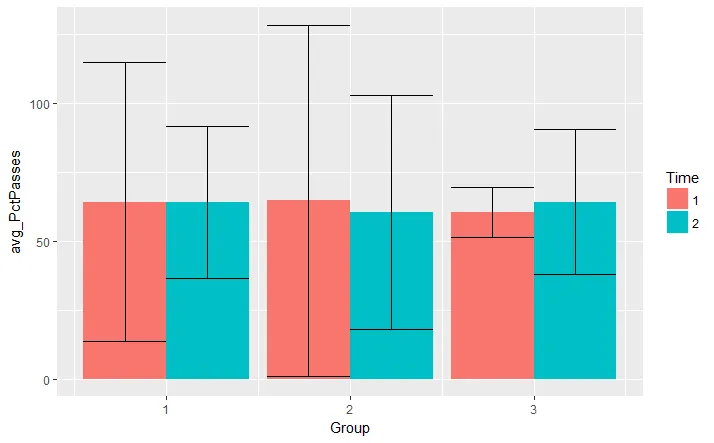
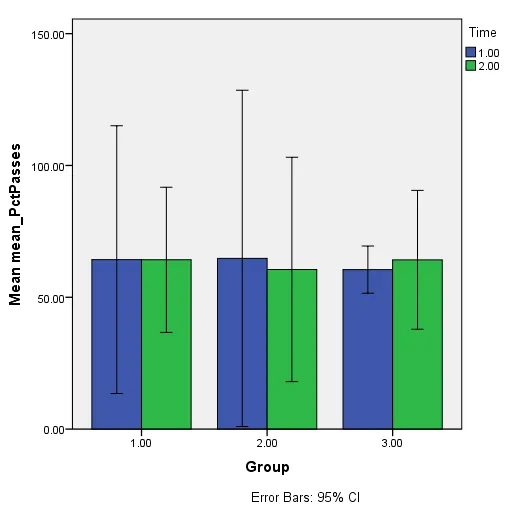
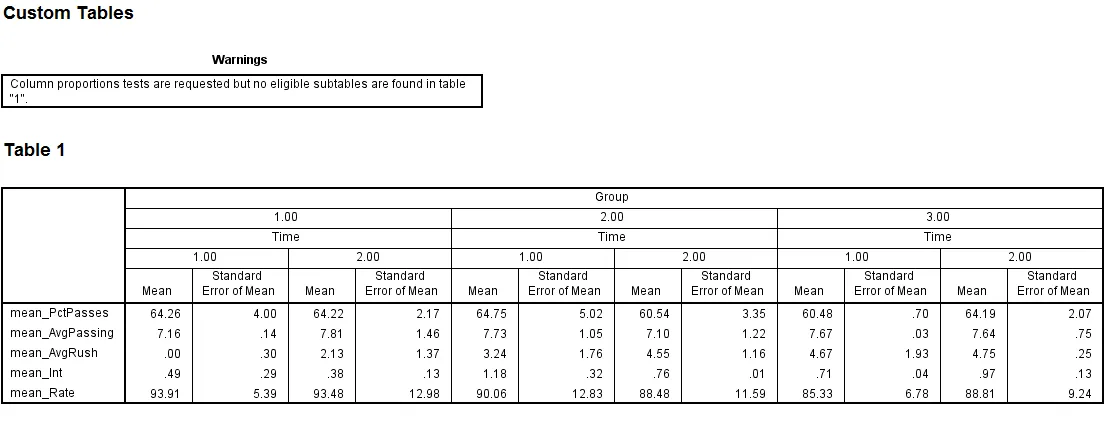
这不允许我根据组和时间对我的数据进行分组。下面是我希望在R中构建的图表示例(显示在SPSS中)。
如果有任何帮助/协助,将不胜感激。如果需要任何澄清,让我知道,我一定会编辑我的帖子。
更新
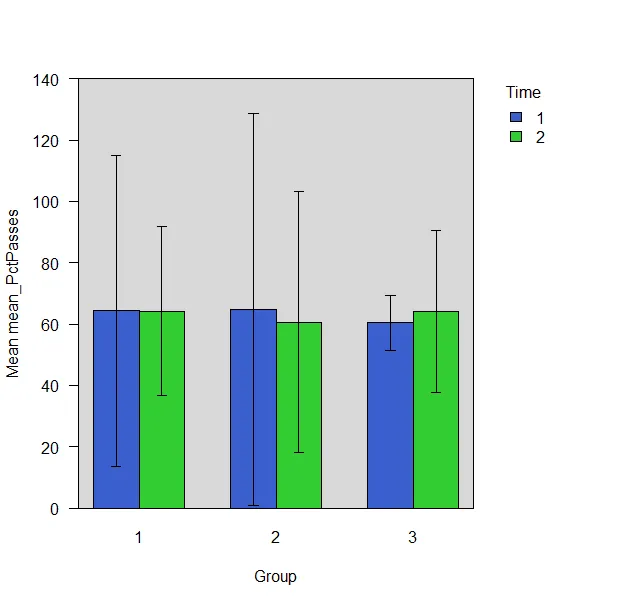
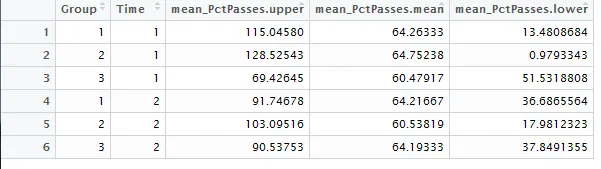
在得到了一些很好的答案(感谢Rob和Steven)之后,我觉得我需要稍微澄清一下我的问题。 我想为每个组(而不是单独地)获取所有统计信息(从mean_PctPasses到mean_Rate)。使用Rmisc显示了一个产生我想要的一个变量的统计信息的函数示例: library(Rmisc) group.UCL(mean_PctPasses~Group+Time , data, FUN=CI) 这仅为mean_PctPasses提供了以下输出 Output Using Rmisc
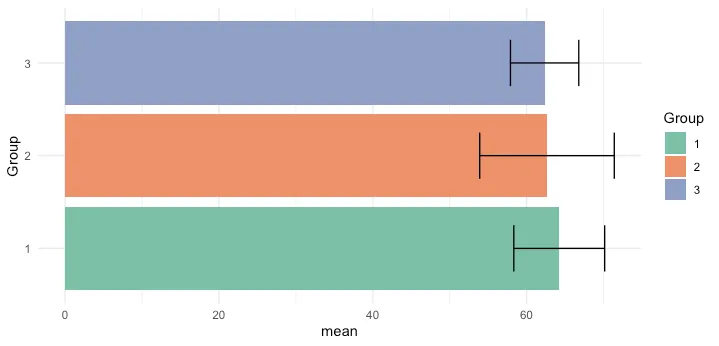
但是我想要的是以下内容(我已经使用Photoshop进行了编辑) 期望输出的图像
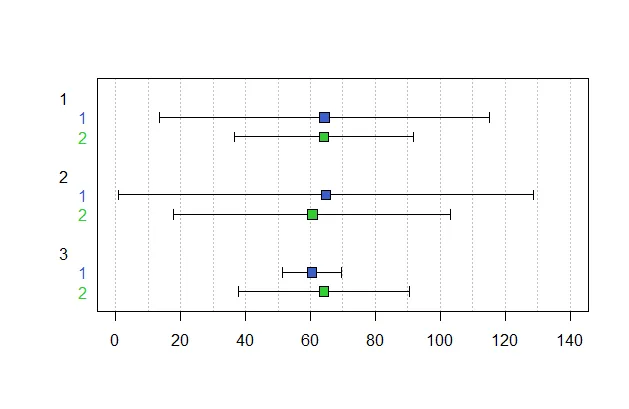
当然,这也可以显示为另一种方向(例如下面的SPSS和SEM示例)。 SPSS中的替代方向示例
{kind=link}
{kind=link}
{kind=link}
{kind=link}
dplyr中的summarise()函数来完成这个任务吗?似乎我在下面的第一个代码块中放置的内容正是您所要求的。或者,您是在寻找一个函数来帮您完成所有工作吗? - Stevenrcompanion包的作者。该包中没有ci.mean函数。但是,有一个groupwiseMean函数可以为组生成置信区间,提供了几种不同的方法。例如:groupwiseMean(PctPasses ~ Group + Time, data = data)。 - Sal Mangiafico