是否可以限制 tesseract 查找的字符集(例如仅查找字母 a-z)?这将大大提高我的识别结果。
7个回答
92
在tessdata/configs目录下创建一个配置文件(例如“letters”)- 通常是 /usr/share/tesseract/tessdata/configs 或 /usr/share/tesseract-ocr/tessdata/configs。
然后将以下行添加到配置文件中:
tessedit_char_whitelist abcdefghijklmnopqrstuvwxyz
...或者可能[a-z]也可以。我不确定。然后像这样调用tesseract:
tesseract input.tif output nobatch letters
这将限制 Tesseract 仅识别所需字符。
- Blomman
7
抱歉回复晚了 - 这很有帮助。谢谢 :) 顺便说一下,正则表达式没有起作用。它可能被字面解释了。 - Danilo Bargen
1SWATI:这是什么类型的图像?尝试清理源图像。例如使用ImageMagick。 - Danilo Bargen
2非常有帮助!我想说Tesseract的文档很糟糕,但实际上我要找的词是“不存在”。谢谢! - zorlack
@DaniloBargen 你所说的清理源图像是什么意思? - user2754681
-1 不起作用。没有这样的文件...如果我创建自定义配置并使用它,它不会产生任何效果。 - Flash Thunder
显示剩余2条评论
31
在最新的4.0版本中,要在配置文件或使用命令行开关-c tessedit_char_whitelist=...中使用白名单,您需要将OCR引擎模式设置为"Original Tesseract only"。这是因为新的"Neural nets LSTM"模式不遵守白名单设置。
4.0版本的正确命令行示例:
tesseract input_file output_file --oem 0 -c tessedit_char_whitelist=abc123
更新:在更新的版本(4.0)中,默认情况下Windows和一些Linux安装程序会安装损坏的eng.traineddata文件。暂时解决方案是用旧版本的文件替换tessdata\eng.traineddata文件。该文件应该约为30MB。否则,您将收到错误:“Tesseract无法加载任何语言!”或类似错误。
tesseract 4.1.1更新
然而,在tesseract 4.1.1中,上述bug已经被修复,也就是说,在tesseract 4.1.1中,以下内容正常运行
tesseract my_image.jpg stdout -l mylang configfile myconfig
其中“myconfig”是位于TESSDATA / configs中的纯文本文件。
load_system_dawg false
load_freq_dawg false
tessedit_char_whitelist ABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789
- Bartłomiej Uliasz
10
1我正在使用pytesseract作为pyt,并在按照上述建议
pyt.image_to_data(im_gray_res, config='-c tessedit_char_whitelist=0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ --psm 11 --oem 0')时遇到以下错误:pytesseract.pytesseract.TesseractError: (1, "Failed loading language 'eng' Tesseract couldn't load any languages! Could not initialize tesseract.")。有没有什么想法可以只使用所需的字符集来完成检测? - SKR是的,我尝试了所有方法,甚至使用了tesseract的CLI,但我在某个地方读到说tesseract 4.0不会遵守字符白名单。因此,我尝试使用选项oem 0,但它甚至无法执行。你能否请在你的端上检查一下--oem 0选项? - SKR
真的吗?当我通过CLI在Ubuntu上安装tesseract时,默认安装了
tesseract 4.0.0-beta.4-138-g2093。你为什么要尝试alpha版本呢?此外,你是否只在白名单中看到输出的字符?你尝试过使用--oem 1/2/3吗? - SKR2是的,你说得对。在新版本中,
eng.traineddata文件已经损坏。我尝试了最新的4.0版本,但是出现了相同的错误。临时解决方案是用旧版本的tessdata\eng.traineddata文件替换它。这个文件应该大约30MB(不像4.0版本安装的那个只有4MB)。 - Bartłomiej Uliasz2是的,我刚刚尝试了GitHub项目链接中最新版本的文件,并用下载的文件替换了
tessdata/eng.trainedddata中的旧文件,在4.0版本上一切都运行得非常完美。 - Bartłomiej Uliasz显示剩余5条评论
26
除了配置文件之外,还有-c标志:
tesseract stdin stdout -c tessedit_char_whitelist=abcdefghijklmnopqrstuvwxyz -psm 6
更新
已确认适用于以下版本:
- 4.1.1
- jmunsch
5
2即使我将其设置为纯净的字母,我仍然会看到消息“检测到31个变音符号”。这很奇怪,因为在白名单中我没有包含任何变音符号或带重音的字符。 - Ed Avis
@EdAvis 请参见:https://github.com/tesseract-ocr/tesseract/wiki/FAQ#diacritics-above-and-below-the-glyph-are-ignoredcause-garbage-output 可能与版本编号有关。我需要更多关于版本编号的研究才能完全理解,但是升级版本、研究 shell 版本和 Unicode 处理或 utf* 可能会显示一些线索。很抱歉我没有完整的答案。 - jmunsch
tesseract 4 不支持白名单。 - wolfgang
2我可以确认在Linux上使用Tesseract 4.1.1效果很好。 - Kingsley
1这可以在Mac上通过Homebrew运行,它使用Tesseract 4.1.1。 - kcdragon
10
针对在Android上使用Tesseract的用户,需要在readOCR函数中设置语言等参数时添加以下代码行:
tesseract.setVariable("tessedit_char_whitelist","ABCDEFGHIJKLMNOPQRSTUVWXYZ");
您可以使用黑名单来排除某些字符。
- user3244591
1
对于那些使用tess4j(Java封装器)的人,请使用“tesseract.setTessVariable()”。 - Pranav
2
我正在使用Ubuntu 18.04.4 LTS操作系统。默认的tesseract版本是4,但是我无法使用白名单功能。于是我将其升级到了版本5,并使用以下命令成功解决了问题。
tesseract sample.jpg stdout -l eng --oem 3 --psm 7
Warning: Invalid resolution 0 dpi. Using 70 instead.
LL £036 GL)
tesseract sample.jpg stdout -l eng --oem 3 --psm 7 -c tessedit_char_whitelist="ABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789"
Warning: Invalid resolution 0 dpi. Using 70 instead.
L4036GL
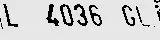{kind=link}
- us2018
2
在Tesseract 4.00版本中,这是无法实现的。您只能微调模型或使用正则表达式从预测中删除额外的字符。原始回答:最初的回答。
- Andrew Ravus
2
不再正确? - jtlz2
在使用Legacy OEM运行tesseract 4.0.0时,是否无法使用白名单?这是tesseract 4.0.0中的一个错误吗?在4.1.1中已经修复了吗?您能确认一下吗? - Yep
0
我的答案完全来自于被接受的答案,并在此添加,以使任何使用Tesseract NuGet包的.NET Windows开发人员受益 - 但请注意我的第二个要点适用于在Windows上使用Tesseract的任何人
- 在存放其他训练数据的
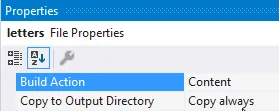
tessdata文件夹内创建一个config文件夹。 - 在
config文件夹内添加一个letters文件。 使用像TextPad这样的编辑器,将其保存为UNIX格式、ANSI编码(我最初尝试了UTF-8 / IBM PC,但tesseract会在我的测试输出中出现错误)。
使用像TextPad这样的编辑器,将其保存为UNIX格式、ANSI编码(我最初尝试了UTF-8 / IBM PC,但tesseract会在我的测试输出中出现错误)。 - 与您的训练文件一样,确保在属性面板中,
letters文件的构建操作设置为Content,并进一步标记为复制到输出目录:
- 按如下方式调用您的tesseract引擎类:
var ocrEng = new TesseractEngine("./tessdata", "eng", EngineMode.Default, "letters");
- bkwdesign
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接