我会尝试解释正在发生的事情和我的问题。
这有点数学化,SO不支持LaTeX,所以不幸的是我不得不使用图片。希望这没关系。
这有点数学化,SO不支持LaTeX,所以不幸的是我不得不使用图片。希望这没关系。


import numpy as np
tau = 2 * np.pi
tau2 = tau * tau
i = complex(0,1)
def solution_f(t, x):
return 0.5 * (np.exp(-tau * i * x) * np.exp((2 - tau2) * i * t) + np.exp(tau * i * x) * np.exp((tau2 + 4) * i * t))
def solution_g(t, x):
return 0.5 * (np.exp(-tau * i * x) * np.exp((2 - tau2) * i * t) - np.exp(tau * i * x) * np.exp((tau2 + 4) * i * t))
for l in range(2, 12):
N = 2 ** l #number of grid points
dx = 1.0 / N #space between grid points
dx2 = dx * dx
dt = dx #time step
t_final = 1
approximate_f = np.zeros((N, 1), dtype = np.complex)
approximate_g = np.zeros((N, 1), dtype = np.complex)
#Insert initial conditions
for k in range(N):
approximate_f[k, 0] = np.cos(tau * k * dx)
approximate_g[k, 0] = -i * np.sin(tau * k * dx)
#Create coefficient matrix
A = np.zeros((2 * N, 2 * N), dtype = np.complex)
#First row is special
A[0, 0] = 1 -3*i*dt
A[0, N] = ((2 * dt / dx2) + dt) * i
A[0, N + 1] = (-dt / dx2) * i
A[0, -1] = (-dt / dx2) * i
#Last row is special
A[N - 1, N - 1] = 1 - (3 * dt) * i
A[N - 1, N] = (-dt / dx2) * i
A[N - 1, -2] = (-dt / dx2) * i
A[N - 1, -1] = ((2 * dt / dx2) + dt) * i
#middle
for k in range(1, N - 1):
A[k, k] = 1 - (3 * dt) * i
A[k, k + N - 1] = (-dt / dx2) * i
A[k, k + N] = ((2 * dt / dx2) + dt) * i
A[k, k + N + 1] = (-dt / dx2) * i
#Bottom half
A[N :, :N] = A[:N, N:]
A[N:, N:] = A[:N, :N]
Ainv = np.linalg.inv(A)
#Advance through time
time = 0
while time < t_final:
b = np.concatenate((approximate_f, approximate_g), axis = 0)
x = np.dot(Ainv, b) #Solve Ax = b
approximate_f = x[:N]
approximate_g = x[N:]
time += dt
approximate_solution = np.concatenate((approximate_f, approximate_g), axis=0)
#Calculate the actual solution
actual_f = np.zeros((N, 1), dtype = np.complex)
actual_g = np.zeros((N, 1), dtype = np.complex)
for k in range(N):
actual_f[k, 0] = solution_f(t_final, k * dx)
actual_g[k, 0] = solution_g(t_final, k * dx)
actual_solution = np.concatenate((actual_f, actual_g), axis = 0)
print(np.sqrt(dx) * np.linalg.norm(actual_solution - approximate_solution))
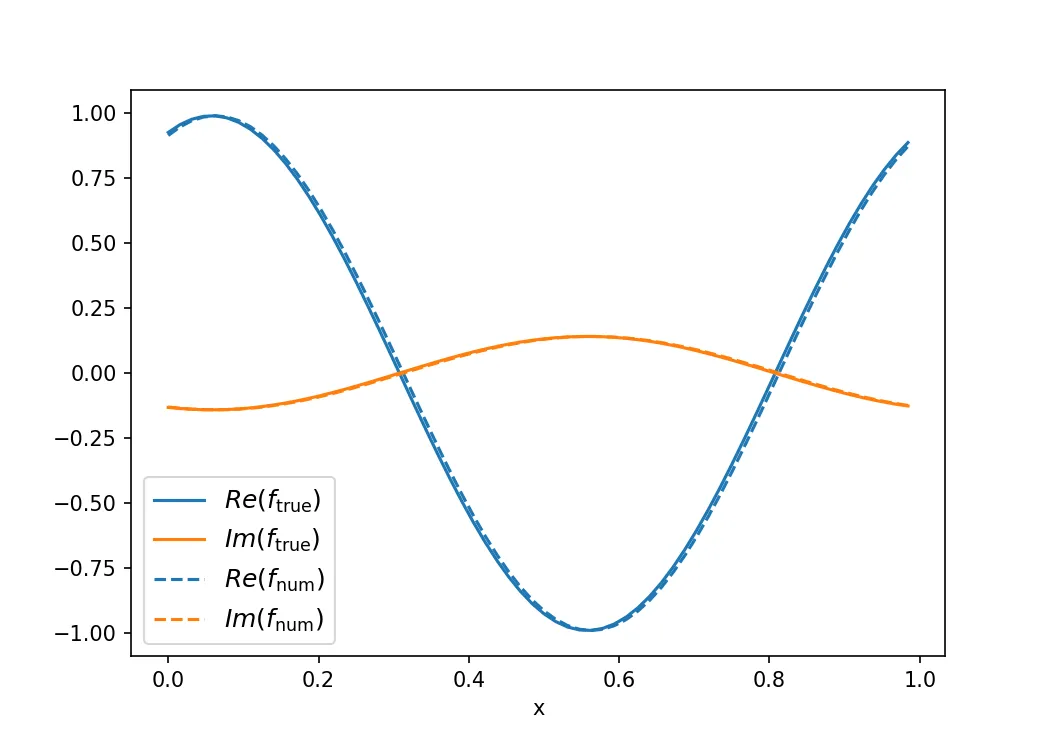
它不起作用。至少在开始时,它不应该这么慢。它应该是无条件稳定的,并收敛到正确的答案。
这里出了什么问题?