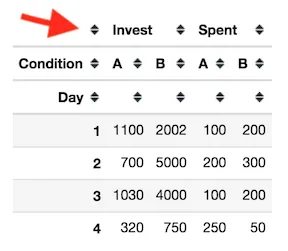
我正在努力制作一个我想要的pandas多级索引分组图。 我有以下虚拟的pandas数据框:
data = {
'Day': [1, 1, 2, 2, 3, 3, 4, 2, 4],
'Condition': ['A', 'B', 'A', 'A', 'A', 'B', 'B', 'B', 'A'],
'Invest': [1100, 2002, 500, 200, 1030, 4000, 750, 5000, 320],
'Spent': [100, 200, 100, 100, 100, 200, 50, 300, 250]
}
index = range(len(data['Day']))
columns = ['Day', 'Condition', 'Invest', 'Spent']
df = pd.DataFrame(data, index=index, columns=columns)
+----+-------+-------------+----------+---------+
| | Day | Condition | Invest | Spent |
|----+-------+-------------+----------+---------|
| 0 | 1 | A | 1100 | 100 |
| 1 | 1 | B | 2002 | 200 |
| 2 | 2 | A | 500 | 100 |
| 3 | 2 | A | 200 | 100 |
| 4 | 3 | A | 1030 | 100 |
| 5 | 3 | B | 4000 | 200 |
| 6 | 4 | B | 750 | 50 |
| 7 | 2 | B | 5000 | 300 |
| 8 | 4 | A | 320 | 250 |
+----+-------+-------------+----------+---------+
我可以使用以下代码获取后续的图表:
df.groupby(['Day', 'Condition']).sum()\
.unstack()\
.plot(subplots=True,
layout=(2,2),
figsize=(8,6));
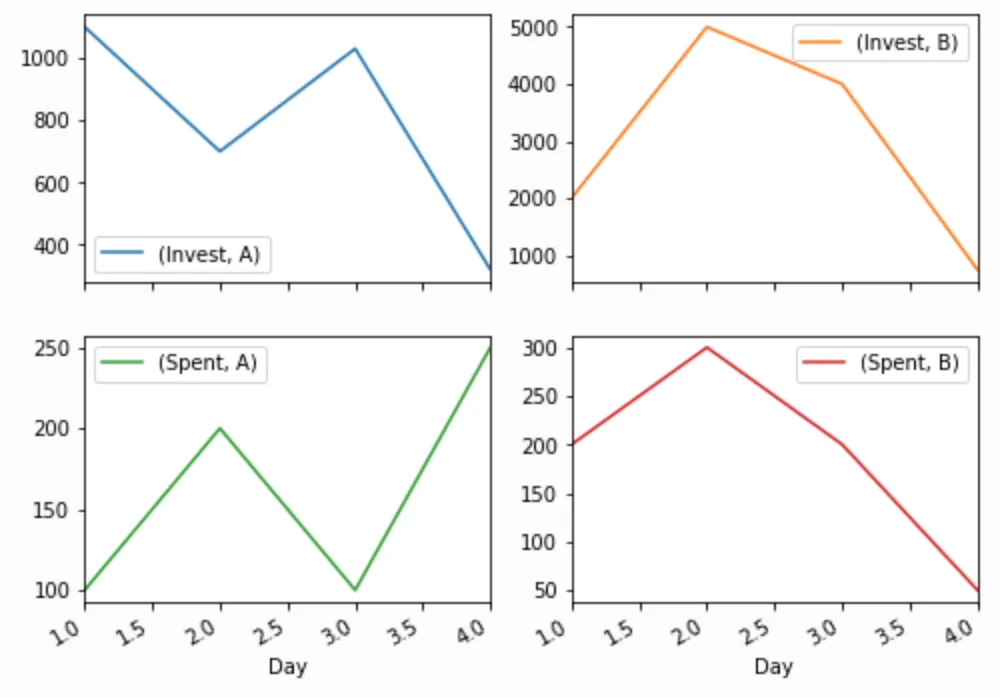
P.S.: "Top Level"是什么意思?我不确定我是否在这里使用了正确的术语,但当我取消堆叠groupby pandas时,在MultiIndex中有各种级别,我的意思是根据如下所示的顶级别对图进行分组:
df.groupby(['Day', 'Condition'])\
.sum()\
.unstack()