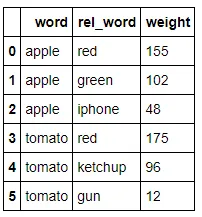
假设我们有以下数据集:
import pandas as pd
data = [('apple', 'red', 155), ('apple', 'green', 102), ('apple', 'iphone', 48),
('tomato', 'red', 175), ('tomato', 'ketchup', 96), ('tomato', 'gun', 12)]
df = pd.DataFrame(data)
df.columns = ['word', 'rel_word', 'weight']