我正在尝试根据类似于这样的数据框中人物的大小来推断一个分类:
Size
1 80000
2 8000000
3 8000000000
...
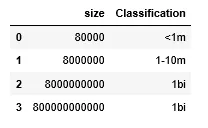
我希望它看起来像这样:
Size Classification
1 80000 <1m
2 8000000 1-10m
3 8000000000 >1bi
...
我理解最理想的过程是应用像这样的lambda函数:
df['Classification']=df['Size'].apply(lambda x: "<1m" if x<1000000 else "1-10m" if 1000000<x<10000000 else ...)
我查看了几篇有关在lambda函数中使用多个if语句的帖子,这是一个示例链接,但是在使用多个if语句时,该语法对我来说无效,但在单个if条件中有效。
因此,我尝试了这个“非常优雅”的解决方案:
df['Classification']=df['Size'].apply(lambda x: "<1m" if x<1000000 else pass)
df['Classification']=df['Size'].apply(lambda x: "1-10m" if 1000000 < x < 10000000 else pass)
df['Classification']=df['Size'].apply(lambda x: "10-50m" if 10000000 < x < 50000000 else pass)
df['Classification']=df['Size'].apply(lambda x: "50-100m" if 50000000 < x < 100000000 else pass)
df['Classification']=df['Size'].apply(lambda x: "100-500m" if 100000000 < x < 500000000 else pass)
df['Classification']=df['Size'].apply(lambda x: "500m-1bi" if 500000000 < x < 1000000000 else pass)
df['Classification']=df['Size'].apply(lambda x: ">1bi" if 1000000000 < x else pass)
看来“通过”这个词似乎也不适用于lambda函数:
df['Classification']=df['Size'].apply(lambda x: "<1m" if x<1000000 else pass)
SyntaxError: invalid syntax
有没有关于在Pandas的apply方法中,一个lambda函数内部使用多个if语句的正确语法建议?无论是多行还是单行解决方案都可以。
任何建议关于在 Pandas 的 apply 方法中,使用 lambda 函数包含多个 if 语句的正确语法。无论是多行还是单行的解决方案对我来说都OK。