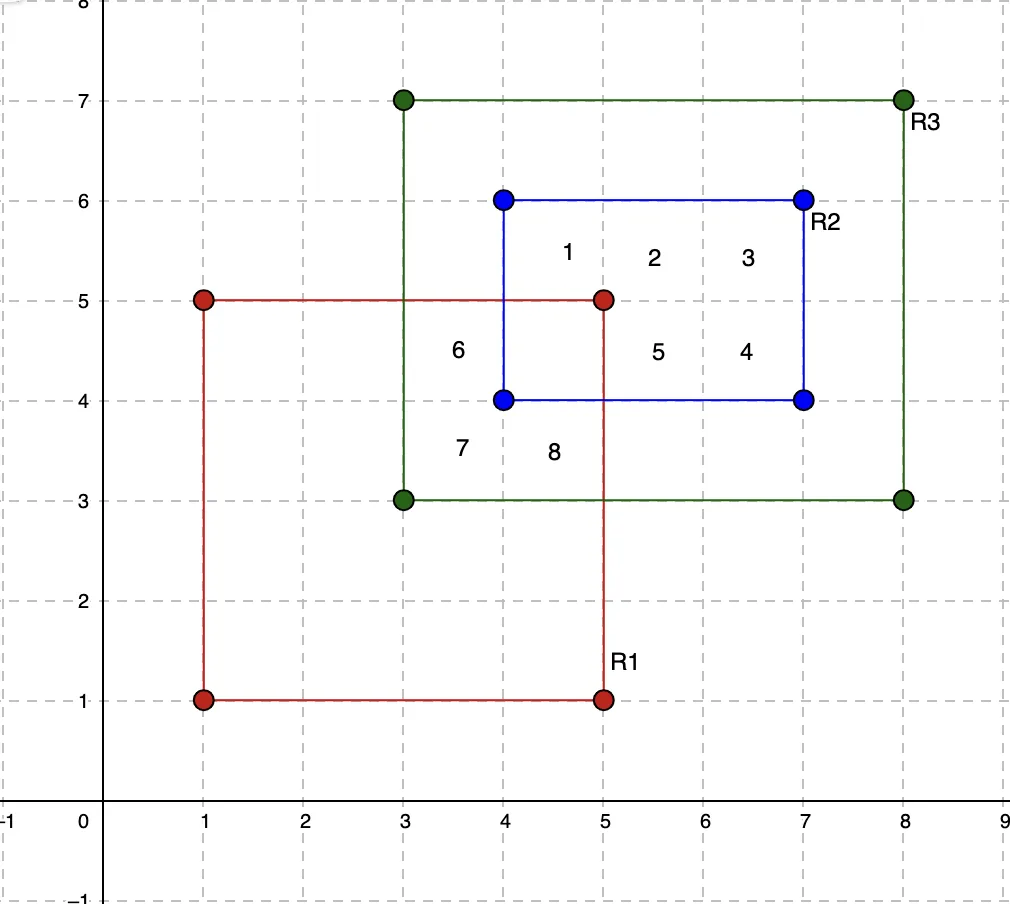
将矩形按其底部坐标x1排序后插入数据结构中。使用自平衡二叉搜索树等数据结构,时间复杂度为O(N.LogN),可以在O(N)的时间内遍历整棵树,其中N为矩形数量。例如:
[R1, R3, R2]
在将矩形插入树中的同时,还需保持所有唯一底部和顶部坐标y1和y2的排序列表。在本例中是:
[1, 3, 4, 5, 6, 7]
现在我们将每个相邻的 y 坐标之间的水平切片视为一维问题(类似于 this answer 中的第一种方法)。
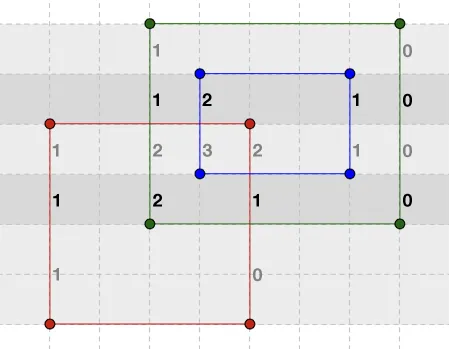
从矩形树的起点开始迭代所有落在此切片中的矩形(记住矩形按y1排序,因此它们在开头分组在一起),并制作一个已排序的唯一x坐标列表,每个值都加1(如果是左坐标)或减1(如果是右坐标)。如果遇到顶部坐标等于切片顶部坐标的矩形,则将其从矩形树中删除,这可以在O(1)内完成。对于示例中的第一个切片,y=1~3,高度为2,如下所示:
[1: +1, 5: -1]
如果我们对其进行迭代,我们会发现一个宽度为4(因此面积为8)的区域是一个矩形的一部分。
对于示例中的第二个切片,其中y=3~4且高度为1,即:
[1: +1, 3: +1, 5: -1, 8, -1]
如果我们对其进行迭代,我们会发现一个宽度为2(因此面积为2)的区域是1个矩形的一部分,一个宽度为2(因此面积为2)的区域是2个矩形的一部分,以及一个宽度为3(因此面积为3)的区域是1个矩形的一部分。因此,任何是k个矩形的一部分的区域都会被添加到总数中。等等。
创建矩形树的时间复杂度为O(N.LogN),创建切片列表的时间复杂度为O(N.LogN),迭代切片的时间复杂度为O(N),在每个切片内创建排序后的x坐标列表的时间复杂度为O(N.LogN),因此总时间复杂度为O(N2.LogN),与矩形有多大、总面积有多大以及矩形或矩形集群之间有多少重叠无关。
O(AT + AU),其中AT是所有矩形面积之和,而AU是并集(或边界框,具体取决于如何在所有网格单元格上进行最终迭代)的面积。虽然理论上复杂度相同,但实践中可能会通过自动分区kd树更快。也就是说,您不会记录每个网格单元格的重叠部分,而是记录每个树单元格的重叠部分,这些单元格可能会更少,具体取决于矩形大小分布情况。 - Nico Schertler