我希望确认一下我是否正确使用了scipy的KD树,因为它似乎比简单暴力法要慢。
我有三个关于此的问题:
Q1.
如果我创建以下测试数据:
nplen = 1000000
# WGS84 lat/long
point = [51.349,-0.19]
# This contains WGS84 lat/long
points = np.ndarray.tolist(np.column_stack(
[np.round(np.random.randn(nplen)+51,5),
np.round(np.random.randn(nplen),5)]))
并创建三个函数:
def kd_test(points,point):
""" KD Tree"""
return points[spatial.KDTree(points).query(point)[1]]
def ckd_test(points,point):
""" C implementation of KD Tree"""
return points[spatial.cKDTree(points).query(point)[1]]
def closest_math(points,point):
""" Simple angle"""
return (min((hypot(x2-point[1],y2-point[0]),y2,x2) for y2,x2 in points))[1:3]
我希望cKD树是最快的,然而 - 运行以下代码:
print("Co-ordinate: ", f(points,point))
print("Index: ", points.index(list(f(points,point))))
%timeit f(points,point)
结果次数 - 简单的暴力方法更快:
closest_math: 1 loops, best of 3: 3.59 s per loop
ckd_test: 1 loops, best of 3: 13.5 s per loop
kd_test: 1 loops, best of 3: 30.9 s per loop
这是因为我使用方式不正确吗?
Q2.
我认为,即使要获得最接近点的排名(而不是距离),仍然需要对数据进行投影。然而,似乎投影和未投影的点给出了相同的最近邻:
def proj_list(points,
inproj = Proj(init='epsg:4326'),
outproj = Proj(init='epsg:27700')):
""" Projected geo coordinates"""
return [list(transform(inproj,outproj,x,y)) for y,x in points]
proj_points = proj_list(points)
proj_point = proj_list([point])[0]
我只是因为我的点分布不够大而没有引入扭曲吗?我重新运行了几次,仍然得到与返回的投影和未投影列表相同的索引。
Q3.
与在(未投影的)纬度/经度上计算haversine或vincenty距离相比,将点投影并计算斜边距离通常更快吗?另外哪个选项更精确?我进行了小型测试:
from math import *
def haversine(origin,
destination):
"""
Find distance between a pair of lat/lng coordinates
"""
lat1, lon1, lat2, lon2 = map(radians, [origin[0],origin[1],destination[0],destination[1]])
dlon = lon2 - lon1
dlat = lat2 - lat1
a = sin(dlat / 2) ** 2 + cos(lat1) * cos(lat2) * sin(dlon / 2) ** 2
c = 2 * asin(sqrt(a))
r = 6371000 # Metres
return (c * r)
def closest_math_unproj(points,point):
""" Haversine on unprojected """
return (min((haversine(point,pt),pt[0],pt[1]) for pt in points))
def closest_math_proj(points,point):
""" Simple angle since projected"""
return (min((hypot(x2-point[1],y2-point[0]),y2,x2) for y2,x2 in points))
结果:
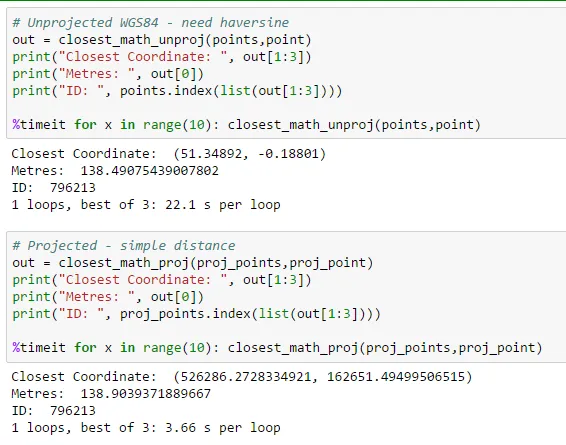
在在线Vincenty计算器上测试,投影坐标似乎是正确的选择:

%timeit -n 10 f(points,point)可能比使用%timeit for x in range(10): f(points,point)更方便。 - Martin Valgur