我正在使用Gnumeric中的
或者,我是否可以设置计算机忽略单元格内的所有行内字符?
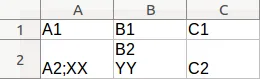
ssconvert命令将一堆ODS文件转换为CSV文件,命令如下:ssconvert -O 'separator=; quoting-mode=never' "f.ods" "f.txt";大多数情况下都很好用。但是有时候,用户在单元格内输入了一个新行符(在Mac上的OpenOffice和LibreOffice中,可以通过按cmd+enter实现)。这会导致生成的CSV文件多出一行,所以原本应该是这样的:
This is some text. Here comes a newline that should be ignored;Some data;Some more data
而实际上得到的是:
This is some text. Here comes a newline
that should be ignored;Some data; Some more data
在转换过程中,是否可以将所有这些单元格内的换行符替换为其他字符,例如*?或者,我是否可以设置计算机忽略单元格内的所有行内字符?