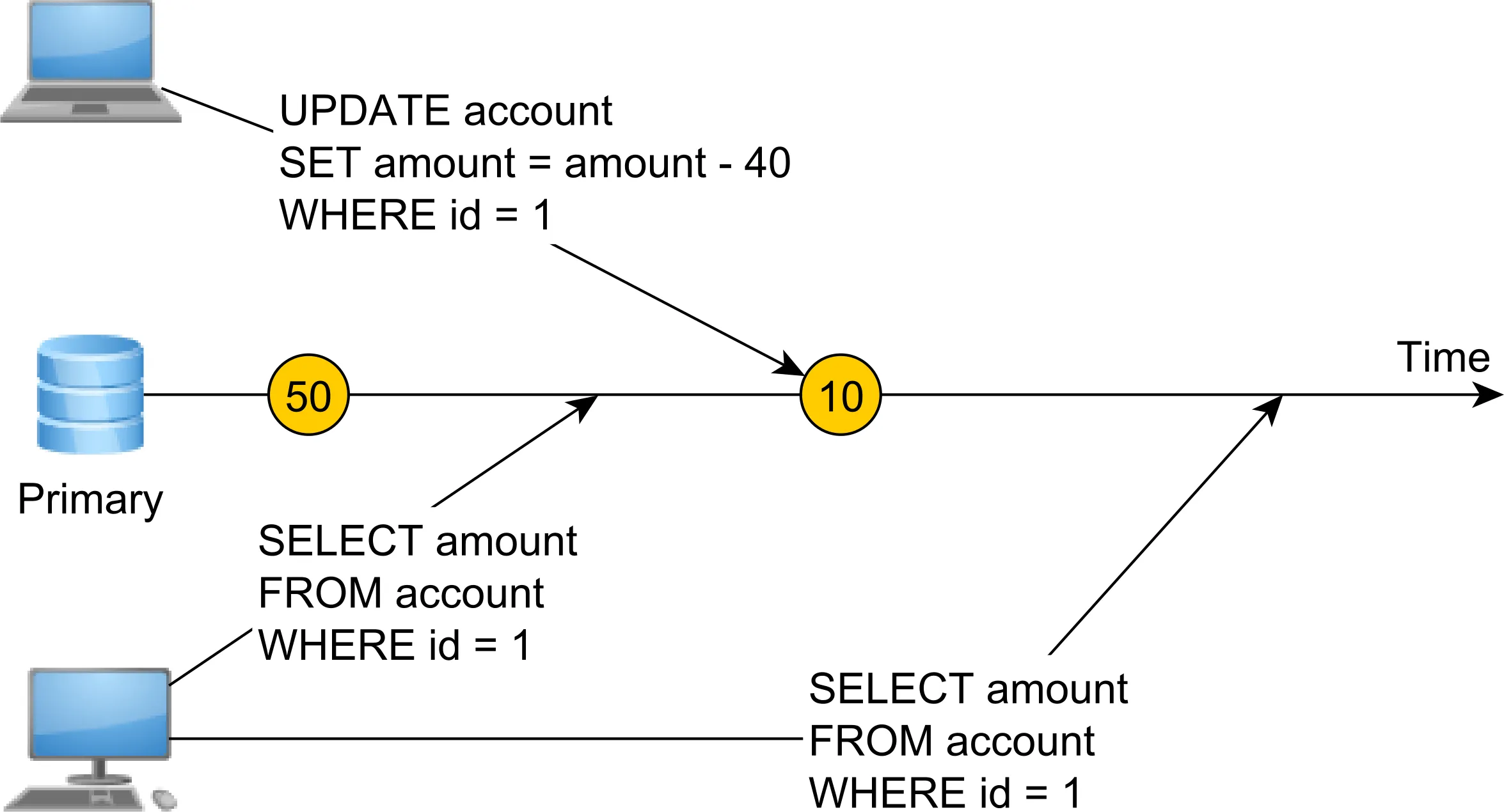
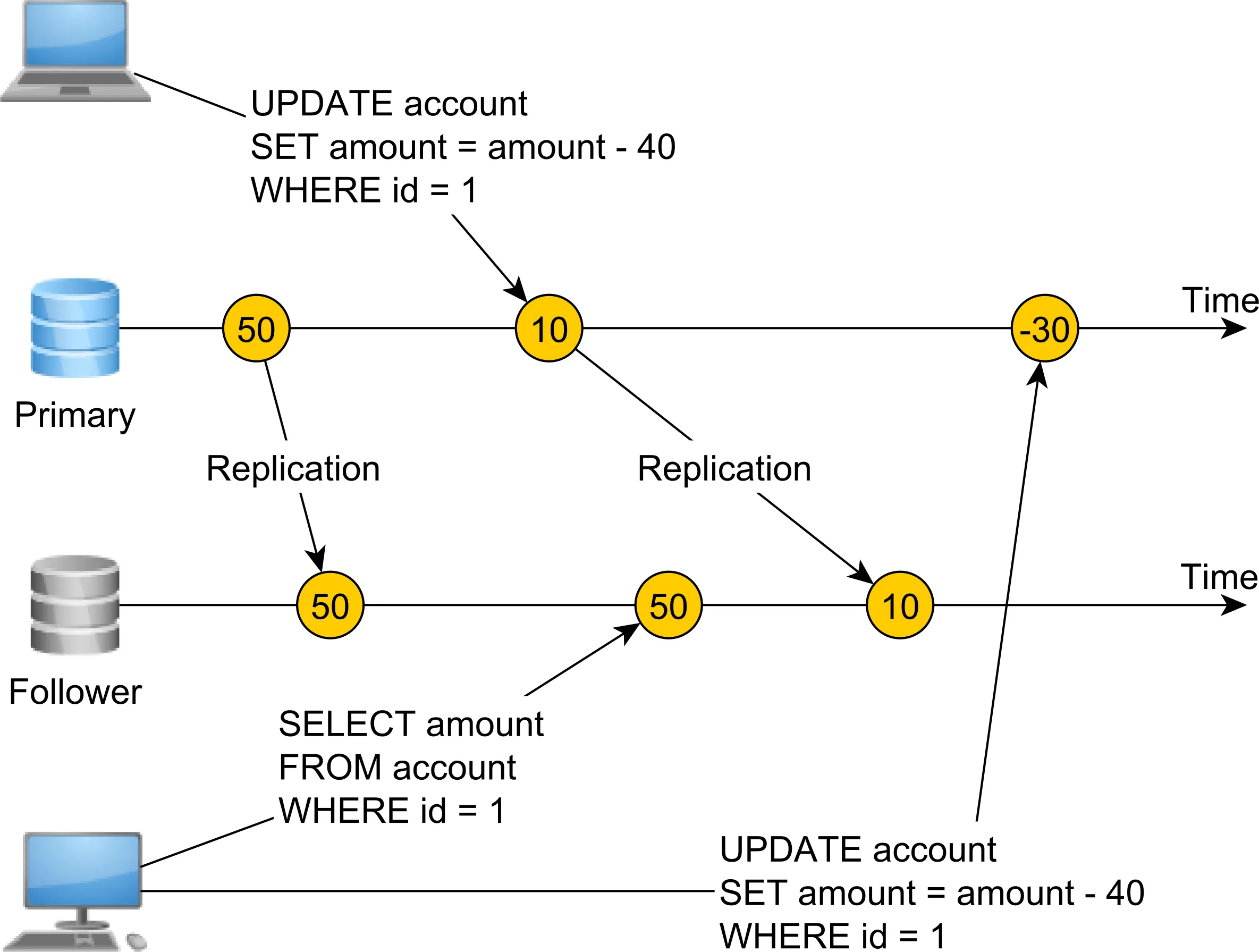
嗯,我认为我可以简洁地回答这个问题。
当我们要判断一个并发对象是否正确时,我们总是试图找到一种方法将偏序扩展为全序。
相比之下,我们可以更容易地识别顺序对象是否正确。
首先,让我们把并发对象放在一边。我们稍后再讨论它。现在让我们考虑一个顺序历史 H_S,顺序历史是一系列事件(即调用和响应)的序列,其中每个调用都立即跟随其对应的响应。(好的,“立即”可能会引起混淆,请考虑单线程程序的执行,当然每个调用和其响应之间有一个时间间隔,但方法是逐个执行的。因此,“立即”意味着没有其他调用/响应可以插入到一对调用_i~响应_i 中)
H_S 可能看起来像:
H_S : I1 R1 I2 R2 I3 R3 ... In Rn
(Ii means the i-th Invoke, and Ri means the i-th Response)
对于历史记录H_S的正确性,我们可以很容易地进行推理,因为没有并发性,我们需要做的就是检查执行是否按照我们期望的方式进行(满足顺序规范的条件)。换句话说,这是一个合法的顺序历史记录。
但现实情况是,我们正在处理一个并发程序。例如,在我们的程序中运行两个线程A和B。每次运行程序时,我们都会得到一个执行历史记录H_C(History_Concurrent)。我们需要像上面的H_S一样将方法调用视为Ii〜Ri。当然,线程A和线程B调用的方法之间必定存在许多重叠。但是每个事件(即调用和响应)都有其实时顺序。因此,A和B调用的所有方法的调用和响应可以映射到一个顺序,该顺序可能如下所示:
H_C : IA1 IB1 RA1 RB1 IB2 IA2 RB2 RA2
顺序似乎有些混乱,实际上只是每个方法调用事件的排序:
thread A: IA1----------RA1 IA2-----------RA2
thread B: | IB1---|---RB1 IB2----|----RB2 |
| | | | | | | |
| | | | | | | |
real-time order: IA1 IB1 RA1 RB1 IB2 IA2 RB2 RA2
------------------------------------------------------>time
我们已经得到了H_C。
那么我们如何检查H_C的执行是否正确呢?我们可以按照以下规则将H_C重新排序为H_RO:
规则:如果一个方法调用m1在另一个m2之前,则m1必须在重新排序后的序列中先于m2。(这意味着如果Ri在H_C中在Ij之前,您必须确保Ri仍然在重新排序后的序列中在Ij之前,i和j没有它们的顺序,我们也可以使用a、b、c...)我们称H_C在此规则下等价于H_RO(history_reorder)。
H_RO具有两个属性:
- 它遵循程序顺序。
- 它保留实时行为。
按照上述规则重新排序H_C,我们可以得到一些顺序历史记录(它们与H_C等效),例如:
H_S1: IA1 RA1 IB1 RB1 IB2 RB2 IA2 RA2
H_S2: IB1 RB1 IA1 RA1 IB2 RB2 IA2 RA2
H_S3: IB1 RB1 IA1 RA1 IA2 RA2 IB2 RB2
H_S4: IA1 RA1 IB1 RB1 IA2 RA2 IB2 RB2
然而,我们无法获得 H_S5:
H_S5: IA1 RA1 IA2 RA2 IB1 RB1 IB2 RB2
因为在H_C中,IB1~RB1完全先于IA2~RA2,所以它不能被重新排序。
现在,有了这些顺序历史,我们如何确认我们的执行历史H_C是正确的?(我强调了历史H_C,这意味着我们现在只关心历史H_C的正确性,而不是并发程序的正确性)
答案很简单,如果至少有一个顺序历史是正确的(符合顺序规范的合法顺序历史),那么历史H_C是可线性化的,我们称合法的H_S为H_C的线性化。而H_C是一个正确的执行。换句话说,它是一个合法的执行,符合我们的预期。如果你有并发编程的经验,你一定写过这样的程序,有时看起来很好,但有时完全错误。
现在我们已经知道了并发程序执行的线性化历史是什么。那么并发程序本身呢?
线性一致性的基本思想是,每个并发历史都等价于某个顺序历史,即满足重新排序规则。如果每个并发历史都有一个线性化(合法的等价顺序历史),则并发程序符合线性一致性条件。现在,我们已经理解了什么是线性一致性。如果我们说我们的并发程序是线性化的,换句话说,它具有线性一致性属性。这意味着每次运行时,历史记录都是线性化的(历史记录符合我们的期望)。因此,显然,线性一致性是一个安全(正确性)属性。
然而,将所有并发历史记录重新排序为顺序历史记录以判断程序是否可线性化的方法仅在原则上可能。在实践中,我们面临着由两位数线程调用的数千个方法调用。我们无法对它们的所有历史记录进行重新排序。我们甚至无法列出一个微不足道的程序的所有并发历史记录。
展示并发对象实现是可线性化的通常方法是为每个方法确定一个线性化点,该点使方法生效。 [《多处理器编程艺术》3.5.1:线性化点]
我们将在“并发对象”的条件下讨论问题。 它与上述基本相同。 并发对象的实现具有一些方法来访问并发对象的数据。 多个线程将共享并发对象。 因此,在调用对象的方法并发访问对象时,并发对象的实现者必须确保并发方法调用的正确性。
他将为每种方法确定一个线性化点。最重要的是理解线性化点的含义。 “方法生效的位置”这个说法真的很难理解。 下面是一些例子:
首先,让我们看一个错误的例子:
int inc_counter() {
int j = i++;
return j;
}
找到错误非常容易。我们可以将 i++ 翻译为:
Load register, address of i
Add register, 1
Store register, address of i
因此,两个线程可以同时执行一个“i ++;”语句,而i的结果似乎只增加了一次。我们可以得到这样的H_C:
thread A: IA1----------RA1(1) IA2------------RA2(3)
thread B: | IB1---|------RB1(1) IB2----|----RB2(2) |
| | | | | | | |
| | | | | | | |
real-time order: IA1 IB1 RA1(1) RB1(1) IB2 IA2 RB2(2) RA2(3)
---------------------------------------------------------->time
无论您尝试重新排序实时订单,都不能找到与 H_C 等效的合法顺序历史记录。
我们应该重写程序:
int inc_counter(){
lock(&lock);
i++;
int j = i;
unlock(&lock);
return j;
}
好的,inc_counter()的线性化点是什么?答案是整个临界区。因为当许多线程重复调用inc_counter()时,临界区将被原子地执行。这可以保证该方法的正确性。该方法的响应是全局变量i的递增值。考虑H_C如下:
thread A: IA1----------RA1(2) IA2-----------RA2(4)
thread B: | IB1---|-------RB1(1) IB2--|----RB2(3) |
| | | | | | | |
| | | | | | | |
real-time order: IA1 IB1 RA1(2) RB1(1) IB2 IA2 RB2(3) RA2(4)
显然,等效的顺序历史是合法的:
IB1 RB1(1) IA1 RA1(2) IB2 RB2(3) IA2 RA2(4) //a legal sequential history
我们已经重新排序了IB1~RB1和IA1~RA1,因为它们在实时订单中重叠,可能会被模糊地重新排序。在H_C的情况下,我们可以推断出IB1~RB1的临界区先进入。
这个例子太简单了。让我们考虑另一个:
void push(T val) {
while (1) {
Node * new_element = allocate(val);
Node * next = top->next;
new_element->next = next;
if ( CAS(&top->next, next, new_element)) {
return;
}
}
}
T pop() {
while (1) {
Node * next = top->next;
Node * nextnext = next->next;
if ( CAS(&top->next, next, nextnext)) {
return next->value;
}
}
}
这是一个无锁栈算法,
充满了漏洞!但不要太在意细节。我只想展示push()和pop()的线性化点。我已经在注释中展示了它们。考虑到许多线程反复调用push()和pop(),它们将在CAS步骤中被排序。其他步骤似乎并不重要,因为无论它们同时执行什么,它们对栈(精确地说是顶部变量)产生的最终影响都取决于CAS步骤的顺序(即线性化点)。如果我们能确保线性化点真正起作用,那么并发栈就是正确的。H_C的图片太长了,但我们可以确认必须存在一个合法的顺序等价于H_C。
所以,如果你正在实现一个并发对象,如何判断你的程序是否正确?你应该确定每个方法的线性化点,并仔细思考(甚至证明)它们将始终保持并发对象的不变量。然后,所有方法调用的偏序关系可以扩展到至少一个合法的总序(事件的顺序历史),满足并发对象的顺序规范。
然后你可以说你的并发对象是正确的。