我不明白,在下面的示例中,如果我们有两个线程,为什么没有释放序列就会出现问题。 我们对原子变量count只进行了2次操作。 如输出所示,count按顺序递减。
来自《C++并发编程实战》,作者:Antony Williams
我提到过,即使在一系列的 read-modify-write 操作中,一个 store 操作与一个原子变量的 load 操作之间存在着 synchronizes-with 关系,并且这些操作都被适当地标记,那么在另一个线程中,甚至存在对该原子变量的 load 操作,这条语句也是成立的。如果 store 操作被标记为 memory_order_release、memory_order_acq_rel 或 memory_order_seq_cst,而 load 操作被标记为 memory_order_consume、memory_order_acquire 或 memory_order_seq_cst,并且链中的每个操作都加载了上一个操作写入的值,则操作链构成一个 release sequence,初始的 store 操作会与最终的 load 操作形成 synchronizes-with 关系(对于 memory_order_acquire 或 memory_order_seq_cst),或者是 dependency-ordered-before(对于 memory_order_consume)。链中的任何原子 read-modify-write 操作都可以具有任何内存顺序(即使是 memory_order_relaxed)。要了解这意味着什么(release sequence)以及它的重要性,请考虑将 atomic 用作共享队列中项目数量的计数器,如以下列表所示。
处理事情的一种方法是让生产数据的线程将项目存储在共享缓冲区中,然后执行 count.store(number_of_items, memory_order_release) #1 来告诉其他线程数据可用。消费队列项的线程可能会执行 count.fetch_sub(1, memory_order_acquire) #2 以从队列中获取一个项目,然后才实际读取共享缓冲区 #4。一旦计数变为零,就没有更多的项目了,线程必须等待 #3。
#include <atomic>
#include <thread>
#include <vector>
#include <iostream>
#include <mutex>
std::vector<int> queue_data;
std::atomic<int> count;
std::mutex m;
void process(int i)
{
std::lock_guard<std::mutex> lock(m);
std::cout << "id " << std::this_thread::get_id() << ": " << i << std::endl;
}
void populate_queue()
{
unsigned const number_of_items = 20;
queue_data.clear();
for (unsigned i = 0;i<number_of_items;++i)
{
queue_data.push_back(i);
}
count.store(number_of_items, std::memory_order_release); //#1 The initial store
}
void consume_queue_items()
{
while (true)
{
int item_index;
if ((item_index = count.fetch_sub(1, std::memory_order_acquire)) <= 0) //#2 An RMW operation
{
std::this_thread::sleep_for(std::chrono::milliseconds(500)); //#3
continue;
}
process(queue_data[item_index - 1]); //#4 Reading queue_data is safe
}
}
int main()
{
std::thread a(populate_queue);
std::thread b(consume_queue_items);
std::thread c(consume_queue_items);
a.join();
b.join();
c.join();
}
输出 (VS2015):
id 6836: 19
id 6836: 18
id 6836: 17
id 6836: 16
id 6836: 14
id 6836: 13
id 6836: 12
id 6836: 11
id 6836: 10
id 6836: 9
id 6836: 8
id 13740: 15
id 13740: 6
id 13740: 5
id 13740: 4
id 13740: 3
id 13740: 2
id 13740: 1
id 13740: 0
id 6836: 7
如果只有一个消费者线程,那么这是没有问题的;fetch_sub() 是一个读操作,并且具有 memory_order_acquire 语义,而存储具有 memory_order_release 语义,因此该存储与加载操作同步,线程可以从缓冲区读取项目。
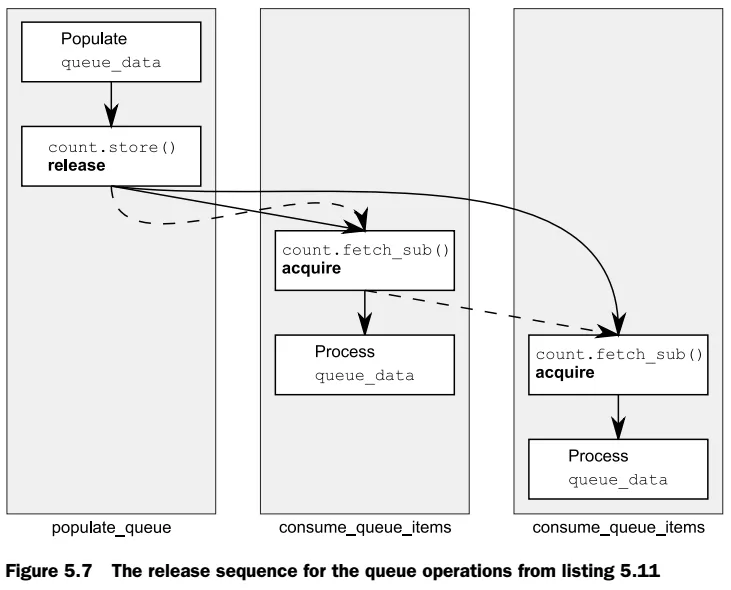
如果有两个线程正在读取,则第二个 fetch_sub() 将看到第一个线程写入的值而不是存储器中写入的值。如果没有关于 release sequence 的规则,那么第二个线程将无法与第一个线程建立 happens-before 关系,除非第一个 fetch_sub() 也具有 memory_order_release 语义,否则在读取共享缓冲区时不安全,这将在两个消费者线程之间引入不必要的同步。如果在 fetch_sub 操作上没有 release sequence 规则或 memory_order_release,那么将没有任何要求将队列数据存储可见于第二个消费者,从而会产生数据竞争。
我应该怎么理解他的意思?两个线程都应该看到
count 的值为 20 吗?但是在我的输出中,count 在线程中被逐个递减。
值得庆幸的是,第一个
fetch_sub()参与了释放序列,因此store()与第二个fetch_sub()同步。两个消费者线程之间仍然没有同步关系。如图5.7所示。图5.7中的虚线显示了释放序列,实线显示了happens-before relationships。