我很好奇什么是随机访问?
我查了一点,但没有找到太多相关信息。我现在的理解是,容器中的“块”是随机放置的(如此处所示)。然后,随机访问意味着我可以访问容器中的每个块,无论位置如何(因此我可以读取第5个位置上的内容,而不必遍历前面的所有块),而使用顺序访问,则需要依次遍历前四个块才能到达第五个块。
{kind=link}
我的理解正确吗?如果不是,那么有人可以向我解释一下什么是随机访问和顺序访问吗?
我很好奇什么是随机访问?
我查了一点,但没有找到太多相关信息。我现在的理解是,容器中的“块”是随机放置的(如此处所示)。然后,随机访问意味着我可以访问容器中的每个块,无论位置如何(因此我可以读取第5个位置上的内容,而不必遍历前面的所有块),而使用顺序访问,则需要依次遍历前四个块才能到达第五个块。
我的理解正确吗?如果不是,那么有人可以向我解释一下什么是随机访问和顺序访问吗?
顺序访问意味着访问第五个元素的成本是访问第一个元素成本的5倍,或者至少与元素在集合中的位置有关联的成本递增。这是因为要访问集合的第五个元素,必须先执行操作以找到第1、2、3和4个元素,因此访问第五个元素需要5个操作。
随机访问意味着访问集合中的任何元素都具有相同的成本。仍然只需要一次操作即可找到集合的第五个元素。
因此,在随机访问数据结构中访问随机元素将具有O(1)的成本,而在顺序访问数据结构中访问随机元素将具有O(n/2) -> O(n)的成本。n/2来自于如果想在一个集合中访问100次随机元素,那么该元素的平均位置将大约在集合中间。因此,对于n个元素的集合,这将变成n/2(在大O符号表示法中可以近似为n)。
你可能会发现很酷:
Hashmap是实现随机访问的数据结构之一。值得注意的是,在哈希映射中发生哈希冲突时,两个冲突元素将存储在哈希映射桶中的一个顺序链表中。这意味着,如果哈希映射存在100%的冲突,则实际上会得到顺序存储。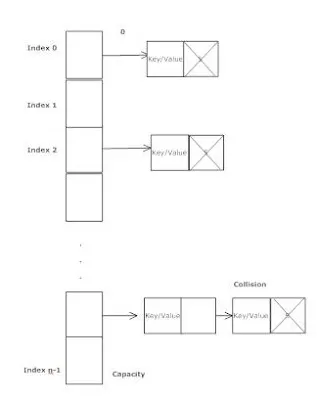
所以:
顺序访问:在n个元素的集合中查找随机元素是Ω(n)、O(n/2)和Θ(1),对于非常大的数字,变成了Ω(n)、O(n)和Θ(1)。
随机访问:在n个元素的集合中查找随机元素是Ω(n/2)、O(1)和Θ(1),对于非常大的数字,变成了Ω(n)、O(1)和Θ(1)。
因此,随机访问具有更好的访问元素性能优势,但顺序存储数据结构在其他方面提供了优势。
针对@sumsar1812的第二次编辑:
我想先说明一下,这是我理解顺序存储的优势/用例的方式,但我对顺序容器的好处理解不如上面的回答那么确定。所以,请在我有误的地方指正我。
顺序存储很有用,因为数据实际上会按顺序存储在内存中。
你可以通过将指针偏移存储单个元素所需的字节数来访问顺序存储数据集的下一个成员。
因此,由于有符号整数需要8个字节来存储,如果你有一个整数固定数组,并且有一个指向第一个整数的指针:
int someInts[5];
someInts[1] = 5;
someInts是指向该数组第一个元素的指针。将1添加到该指针只是通过8个字节偏移其在内存中的指向位置。
(someInts+1)* //returns 5
std::vector<T>和std::list<T>。向量存储值的数组,而列表存储值的链接列表。前者在内存中按顺序存储,这使得任意随机访问变得高效:计算任何元素的位置就像计算下一个元素的位置一样快。因此,顺序存储为您提供了有效的随机访问,并且迭代器是随机访问迭代器。vec.at(n)或者编译器优化不佳)。重要的区别在于,例如,向量和列表。 - Michael Urman// random access. picking elements out, regardless of ordering or sequencing.
// The important factor is that we are selecting items by some kind of
// index.
auto a = some_container[25];
auto b = some_container[1];
auto c = some_container["hi"];
// sequential access. Here, there is no need for an index.
// This implies that the container has a concept of ordering, where an
// element has neighbors
for(container_type::iterator it = some_container.begin();
it != some_container.end();
++ it)
{
auto d = *it;
}