我最近在研究CNN,想知道softmax公式中的温度参数是什么作用?为什么要使用高温度来看到更软的概率分布?Softmax Formula
为什么在softmax中要使用温度?
49
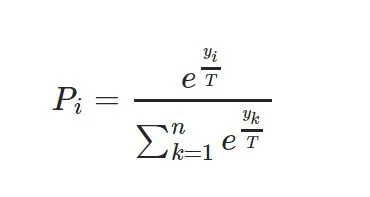{kind=link}
- Sara
3
6欢迎来到SO,这里是关于具体编码问题的平台;有关机器学习理论和方法的问题不属于本站的讨论范围,请前往Cross Validated发布。 - desertnaut
2我投票关闭此问题,因为它与[帮助中定义的编程]无关,而是涉及ML理论。 - desertnaut
@desertnaut 我打算将这个问题复制到datascience.SE上。在2023年,我们有没有更好的导入/导出错误位置页面的工具? - alchemy
1个回答
85
使用温度函数的一个原因是改变神经网络计算输出分布。根据以下公式将其添加到logits向量中:
这将改变最终概率。您可以选择任何T值(T越高,分布将更“柔和” - 如果为1,则输出分布将与正常softmax输出相同)。我所说的“柔和”是指模型基本上对其预测不太有信心。随着T越接近0,“分布”变得越“硬”。
a)样本“硬”softmax概率:
至于为什么较高的温度会导致更柔和的分布,这与指数函数有关。温度参数对较大的logits进行惩罚要比对较小的logits进行惩罚更多。指数函数是一个“增加函数”。因此,如果一个术语已经很大,则通过小量惩罚它使其变得比小术语更小(%方面)。
下面是我的意思:
现在让我们用一个温度,比如说1.5来“惩罚”这个术语:
=exp(/)/ ∑exp(/),其中 是温度参数。这将改变最终概率。您可以选择任何T值(T越高,分布将更“柔和” - 如果为1,则输出分布将与正常softmax输出相同)。我所说的“柔和”是指模型基本上对其预测不太有信心。随着T越接近0,“分布”变得越“硬”。
a)样本“硬”softmax概率:
[0.01,0.01,0.98]
b)样本“软”softmax概率:[0.2,0.2,0.6]
'a'是更“硬”的分布。您的模型非常自信地对其预测。但是,在许多情况下,您不希望模型这样做。例如,如果您正在使用RNN生成文本,您基本上是从输出分布中进行采样,并选择采样的单词作为输出令牌(和下一个输入)。如果您的模型非常自信,它可能会产生非常重复和无聊的文本。您希望它生成更多样化的文本,而它不会生成这种文本,因为在采样过程正在进行时,大部分概率质量将集中在少数令牌中,因此您的模型会一遍又一遍地选择一组单词。为了使其他单词也有机会被采样,您可以插入温度变量并生成更多样化的文本。至于为什么较高的温度会导致更柔和的分布,这与指数函数有关。温度参数对较大的logits进行惩罚要比对较小的logits进行惩罚更多。指数函数是一个“增加函数”。因此,如果一个术语已经很大,则通过小量惩罚它使其变得比小术语更小(%方面)。
下面是我的意思:
exp(6) ~ 403
exp(3) ~ 20
现在让我们用一个温度,比如说1.5来“惩罚”这个术语:
exp(6/1.5) ~ 54
exp(3/1.5) ~ 7.4
您可以看到,在百分比方面,术语越大,当温度用于惩罚它时,它就会缩小得越多。当较大的对数缩小超过较小的对数时,更多的概率质量(由softmax计算)将被分配给较小的对数。
- Zain Sarwar
3
请分享您获取信息的来源。谢谢! - Sachin
这只是数学。 - Zain Sarwar
我理解您的回答非常好,并且感谢您详细的解释。但是,这个答案无法在任何正式的场合作为参考发布。因此,我正在调查是否有任何书籍/研究论文可以解释它。 - Sachin
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接
- 相关问题
- 16 如何在Keras中更改softmax输出的温度
- 24 在深度神经网络中,为什么要使用1x1卷积?
- 21 为什么只在输出层使用softmax而不在隐藏层使用?
- 3 为什么在图像处理中要使用Unsqueeze()函数?
- 231 为什么使用softmax而不是标准归一化?
- 4 Caffe:带温度参数的Softmax
- 3 为什么需要softmax函数?为什么不使用简单的归一化?
- 4 为什么不使用输出张量的最大值而是使用Softmax函数?
- 5 为什么Softmax分类器的梯度要除以批次大小(CS231n)?
- 8 在tf.keras中,使用softmax作为顺序层和在密集层中使用softmax作为激活函数有什么区别?