我有非常大的表格(3000万行),希望将其作为数据框在R中加载。虽然
我知道使用
read.table()具有许多方便的功能,但实现中似乎有很多逻辑会减慢速度。在我的情况下,我假设事先知道列的类型,该表不包含任何列标题或行名称,并且没有任何我需要担心的病态字符。我知道使用
scan()将表格读入列表可能非常快,例如:datalist <- scan('myfile',sep='\t',list(url='',popularity=0,mintime=0,maxtime=0)))
但是,我尝试将其转换为数据框时,似乎会使以上代码的性能降低6倍:
df <- as.data.frame(scan('myfile',sep='\t',list(url='',popularity=0,mintime=0,maxtime=0))))
有更好的方法吗?或者可能完全不同的解决问题的方法?
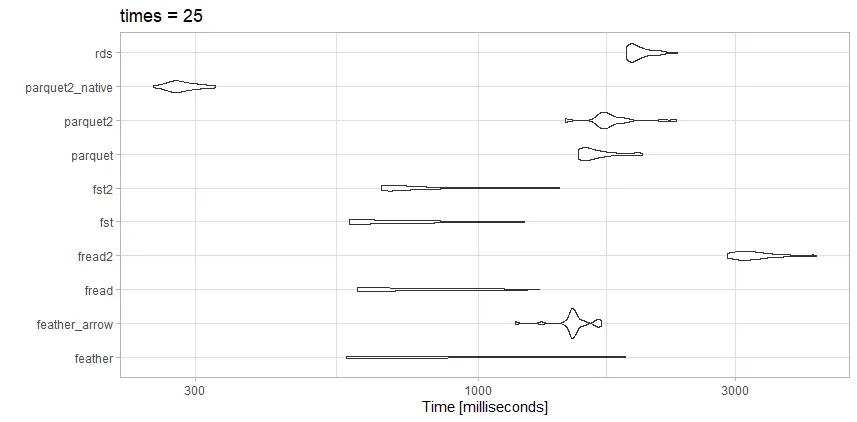
feather的读取速度更快,但它使用了更多的存储空间。 - Z boson