我正在寻找一种方法来有效地对固定目标周围随机选择的采样横断面进行排序。这些横断面生成后,需要按空间意义上有意义的方式进行排序,从而使行进路线距离最小化。这可以通过确保当前横断面的终点尽可能靠近下一个横断面的起点来实现。此外,不能重复使用任何横断面。
因为有数千个横断面需要排序,而手动完成这个任务非常繁琐,所以我正在尝试使用R自动化这个过程。我已经生成了横断面,每个横断面都有一个起点和终点,其位置使用360度系统表示(例如,0是北,90是东,180是南,270是西)。我还生成了一些代码,似乎指示了下一个横断面的起点和ID,但是这段代码存在一些问题:(1)它可能会在考虑起点和终点时产生错误,(2)它无法实现我最终需要的结果,(3)代码本身似乎过于复杂,我不得不想知道是否有更简单的方法来完成这个任务。
理想情况下,代码应该将横断面重新排序,使其与应飞行的顺序相匹配,而不是最初输入的顺序。
数据
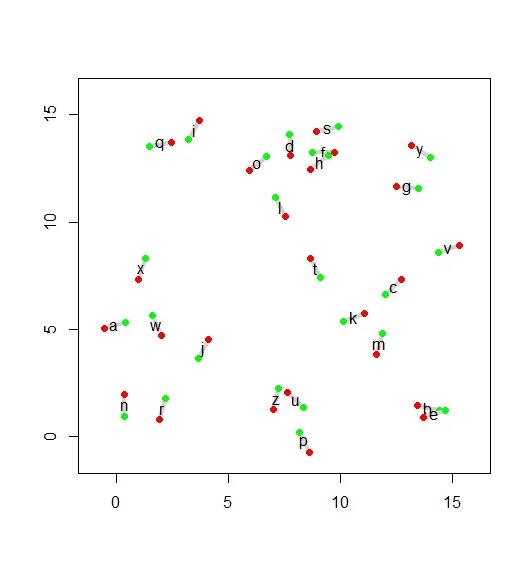
为了简单起见,假设有10条需要排序的横断面。
# Transect ID for the start point
StID <- c(seq(1, 10, 1))
# Location of transect start point, based on a 360-degree circle
StPt <- c(342.1, 189.3, 116.5, 67.9, 72, 208.4, 173.2, 97.8, 168.7, 138.2)
# Transect ID for the end point
EndID <- c(seq(1, 10, 1))
# Location of transect start point, based on a 360-degree circle
EndPt <- c(122.3, 313.9, 198.7, 160.4, 166, 26.7, 312.7, 273.7, 288.8, 287.5)
# Dataframe
df <- cbind.data.frame(StPt, StID, EndPt, EndID)
我尝试过的方法
请随意忽略这段代码,因为必须有更好的方法,而且它并没有真正实现预期的结果。目前,我正在使用一个嵌套的for循环,非常难以直观地跟踪,但这是迄今为止我最好的尝试。
# Create two new columns that will be populated using a loop
df$StPt_Next <- NA
df$ID_Next <- NA
# Also create a list to be populated as end and start points are matched
used <- c(df$StPt[1]) #puts the start point of transect #1 into the used vector since we will start with 1 and do not want to have it used again
# Then, for every row in the dataframe...
for (i in seq(1,length(df$EndPt)-1, 1)){ # Selects all rows except the last one as the last transect should have no "next" transect
# generate some print statements to indicate that the script is indeed running while you wait....
print(paste("######## ENDPOINT", i, ":", df$EndPt[i], " ########"))
print(paste("searching for a start point that fits criteria to follow this endpoint",sep=""))
# sequentially select each end point
valueEndPt <- df[i,1]
# and order the index by taking the absolute difference of end and start points and, if this value is greater than 180, also subtract from 360 so all differences are less than 180, then order differences from smallest to largest
orderx <- order(ifelse(360-abs(df$StPt-valueEndPt) > 180,
abs(df$StPt-valueEndPt),
360-abs(df$StPt-valueEndPt)))
tmp <- as.data.frame(orderx)
# specify index value
index=1
# for as long as there is an "NA" present in the StPt_Next created before for loop...
while (is.na(df$StPt_Next[i])) {
#select the value of the ordered index in sequential order
j=orderx[index]
# if the start point associated with a given index is present in the list of used values...
if (df$StPt[j] %in% used){
# then have R print a statement indicate this is the case...
print(paste("passing ",df$StPt[j], " as it has already been used",sep=""))
# and move onto the next index
index=index+1
# break statement intended to skip the remainder of the code for values that have already been used
next
# if the start point associated with a given index is not present in the list of used values...
} else {
# then identify the start point value associated with that index ID...
valueStPt <- df$StPt[j]
# and have R print a statement indicating an attempt is being made to use the next value
print(paste("trying ",df$StPt[j],sep=""))
# if the end transect number is different from the start end transect number...
if (df$EndID[i] != df$StID[j]) {
# then put the start point in the new column...
df$StPt_Next[i] <- df$StPt[j]
# note which record this start point came from for ease of reference/troubleshooting...
df$ID_Next[i] <- j
# have R print a statement that indicates a value for the new column has beed selected...
print(paste("using ",df$StPt[j],sep=""))
# and add that start point to the list of used ones
used <- c(used,df$StPt[j])
# otherwise, if the end transect number matches the start end transect number...
} else {
# keep NA in this column and try again
df$StPt_Next[i] <- NA
# and indicate that this particular matched pair can not be used
print(paste("cant use ",valueStPt," as the column EndID (related to index in EndPt) and StID (related to index in StPt) values are matching",sep=""))
}# end if else statement to ensure that start and end points come from different transects
# and move onto the next index
index=index+1
}# end if else statement to determine if a given start point still needs to be used
}# end while loop to identify if there are still NA's in the new column
}# end for loop
输出结果
当代码没有产生明确的错误时,比如提供的示例数据,输出结果如下:
StPt StID EndPt EndID StPt_Next ID_Next
1 342.1 1 122.3 1 67.9 4
2 189.3 2 313.9 2 173.2 7
3 116.5 3 198.7 3 97.8 8
4 67.9 4 160.4 4 72.0 5
5 72.0 5 166.0 5 116.5 3
6 208.4 6 26.7 6 189.3 2
7 173.2 7 312.7 7 168.7 9
8 97.8 8 273.7 8 138.2 10
9 168.7 9 288.8 9 208.4 6
10 138.2 10 287.5 10 NA NA
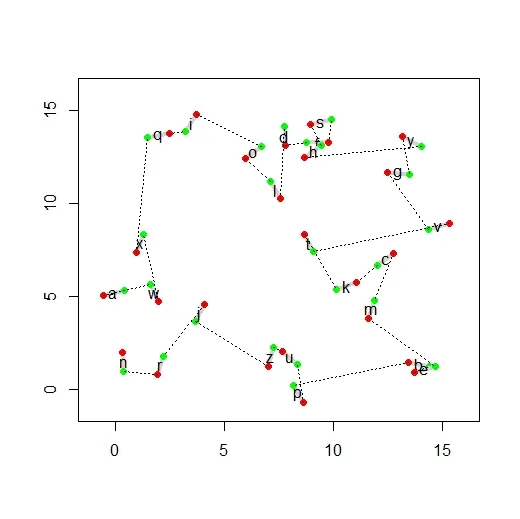
最后两列是代码生成并添加到原始数据框中的。StPt_Next有下一个最近起点的位置,ID_Next表示与该下一个起点位置相关联的横断面ID。ID_Next列表明应按以下顺序飞行横断面:1、4、5、3、8、10、NA(即结束),2、7、9、6形成自己的循环回到2。
有两个具体问题我解决不了:
(1)存在形成一条连续序列的问题。我认为这与1成为起始横断面,10成为最后一横断面有关,但不知道如何在代码中指示倒数第二个横断面必须与10匹配,以便序列包括所有10个横断面,然后以表示最终结束点的"NA"终止。
(2)为了真正自动化这个过程,在修复由于过早引入"NA"作为ID_next导致序列提前终止之后,将创建一个新列,允许根据最有效的进展重新排序横断面,而不是基于它们的EndID/StartID的原始顺序。
预期结果
如果我们假装我们只有6个要排序的横断面,并忽略由于过早引入"NA"而无法排序的4个横断面,那么预期的结果如下:
StPt StID EndPt EndID StPt_Next ID_Next TransNum
1 342.1 1 122.3 1 67.9 4 1
4 67.9 4 160.4 4 72.0 5 2
5 72.0 5 166.0 5 116.5 3 3
3 116.5 3 198.7 3 97.8 8 4
8 97.8 8 273.7 8 138.2 10 5
10 138.2 10 287.5 10 NA NA 6
编辑:关于代码明确生成的错误信息的说明
如前所述,该代码存在一些缺陷。另一个缺陷是,在尝试排序更多的横断面时,它经常会产生错误。我不确定在过程的哪个步骤中生成了错误,但我猜测这可能与无法匹配最后几个横断面有关,可能是由于没有达到“orderx”设定的标准。打印语句显示“trying NA”而不是数据库中的起点,导致出现此错误:“if (df$EndID[i]!= df$StID[j]) { :missing value where TRUE/FALSE needed”。我推测需要另一个if-else语句,以某种方式指示“如果余下的点不符合orderx的条件,则强制将它们与剩余的任何横断面相匹配,以便为所有内容分配StPt_Next和ID_Next”。
这里是一个更大的数据集,将生成错误:
EndPt <- c(158.7,245.1,187.1,298.2,346.8,317.2,74.5,274.2,153.4,246.7,193.6,302.3,6.8,359.1,235.4,134.5,111.2,240.5,359.2,121.3,224.5,212.6,155.1,353.1,181.7,334,249.3,43.9,38.5,75.7,344.3,45.1,285.7,155.5,183.8,60.6,301,132.1,75.9,112,342.1,302.1,288.1,47.4,331.3,3.4,185.3,62,323.7,188,313.1,171.6,187.6,291.4,19.2,210.3,93.3,24.8,83.1,193.8,112.7,204.3,223.3,210.7,201.2,41.3,79.7,175.4,260.7,279.5,82.4,200.2,254.2,228.9,1.4,299.9,102.7,123.7,172.9,23.2,207.3,320.1,344.6,39.9,223.8,106.6,156.6,45.7,236.3,98.1,337.2,296.1,194,307.1,86.6,65.5,86.6,296.4,94.7,279.9)
StPt <- c(56.3,158.1,82.4,185.5,243.9,195.6,335,167,39.4,151.7,99.8,177.2,246.8,266.1,118.2,358.6,357.9,99.6,209.9,342.8,106.5,86.4,35.7,200.6,65.6,212.5,159.1,297,285.9,300.9,177,245.2,153.1,8.1,76.5,322.4,190.8,35.2,342.6,8.8,244.6,202,176.2,308.3,184.2,267.2,26.6,293.8,167.3,30.5,176,74.3,96.9,186.7,288.2,62.6,331.4,254.7,324.1,73.4,16.4,64,110.9,74.4,69.8,298.8,336.6,58.8,170.1,173.2,330.8,92.6,129.2,124.7,262.3,140.4,321.2,34,79.5,263,66.4,172.8,205.5,288,98.5,335.2,38.7,289.7,112.7,350.7,243.2,185.4,63.9,170.3,326.3,322.9,320.6,199.2,287.1,158.1)
EndID <- c(seq(1, 100, 1))
StID <- c(seq(1, 100, 1))
df <- cbind.data.frame(StPt, StID, EndPt, EndID)
非常感谢任何建议!