为了实现这一点,我们可以定义一系列唯一的前向-后向传递过程,并指定操作之间的依赖关系,然后将它们
[1]用
tf.group组合在一起,在单个会话运行中执行。
我的示例为拟合50个二维高斯斑点定义了一个感知器层。该代码在tensorboard中生成以下图形:
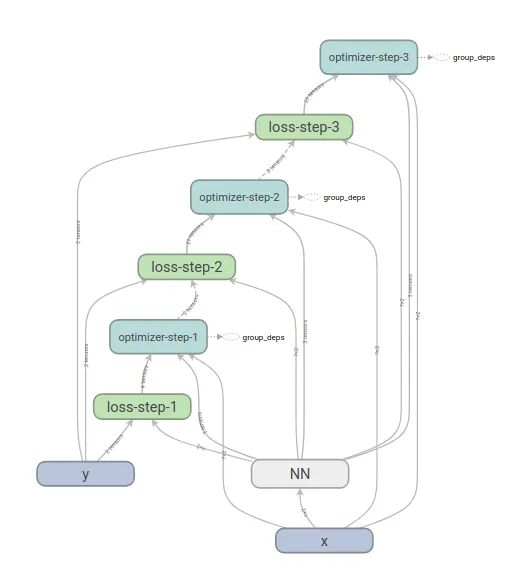
为了测试正确性,我使用相同的初始化值进行了两次训练。第一次使用单个前向-后向传递步骤,第二次使用3个步骤作为单个操作组合:
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
for i in range(12):
loss_val = loss_op.eval(feed_dict={x:x_train, y:y_train})
print(i, '-->', "{0:.3f}".format(loss_val))
_ = sess.run(train_op, feed_dict={x:x_train, y:y_train})
这显然对应着3个步骤。
完整示例:
from sklearn.datasets import make_blobs
import tensorflow as tf
import numpy as np
tf.reset_default_graph()
times_to_apply = 3
with tf.name_scope('x'):
x = tf.placeholder(tf.float32, shape=(None, 2))
with tf.name_scope('y'):
y = tf.placeholder(tf.int32, shape=(50))
logits = tf.layers.dense(inputs=x,
units=2,
name='NN',
kernel_initializer=tf.initializers.ones,
bias_initializer=tf.initializers.zeros)
optimizer = tf.train.GradientDescentOptimizer(0.01)
with tf.name_scope('loss-step-1'):
xentropy = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=y, logits=logits)
loss_op = tf.reduce_mean(xentropy)
with tf.name_scope('optimizer-step-1'):
grads_and_vars = optimizer.compute_gradients(loss_op)
applied_grads = optimizer.apply_gradients(grads_and_vars)
all_grads_and_vars = [grads_and_vars]
all_applied_grads = [applied_grads]
all_loss_ops = [loss_op]
for i in range(times_to_apply - 1):
with tf.control_dependencies([all_applied_grads[-1]]):
with tf.name_scope('loss-step-' + str(i + 2)):
xentropy = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=y, logits=logits)
all_loss_ops.append(tf.reduce_mean(xentropy))
with tf.control_dependencies([all_loss_ops[-1]]):
with tf.name_scope('optimizer-step-' + str(i + 2)):
all_grads_and_vars.append(optimizer.compute_gradients(all_loss_ops[-1]))
all_applied_grads.append(optimizer.apply_gradients(all_grads_and_vars[-1]))
train_op = tf.group(all_applied_grads)
[1] @eqzx是完全正确的。没有必要将操作分组在一起。为了达到相同的效果,我们可以仅执行最终优化器步骤,并使用明确定义的依赖项。
optimizer.apply_gradients呢? - Jie.Zhou