让我们试试:
import pandas as pd
import numpy as np
import networkx as nx
import matplotlib.pyplot as plt
df = pd.DataFrame({'number':['123','234','345'],'contactnumber':['234','345','123'],'callduration':[1,2,4]})
df
G = nx.from_pandas_edgelist(df,'number','contactnumber', edge_attr='callduration')
durations = [i['callduration'] for i in dict(G.edges).values()]
labels = [i for i in dict(G.nodes).keys()]
labels = {i:i for i in dict(G.nodes).keys()}
fig, ax = plt.subplots(figsize=(12,5))
pos = nx.spring_layout(G)
nx.draw_networkx_nodes(G, pos, ax = ax, labels=True)
nx.draw_networkx_edges(G, pos, width=durations, ax=ax)
_ = nx.draw_networkx_labels(G, pos, labels, ax=ax)
输出:
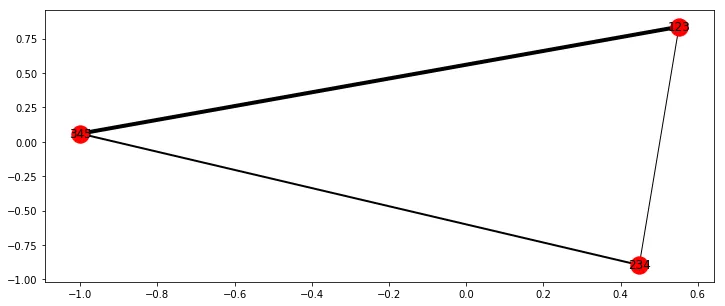
(注:该段文字是对输出结果的描述,图片已被删除)
df[df.callduration.max() == df.callduration]- Scott Boston