我目前正在开发一种基于png文件格式的专有文件格式。到目前为止,我已经完成了所有工作,但它不起作用:-p。我实现的deflate解压器运行良好,但png解码器不想表现出良好的性能,因此我查看了原始的png文件。
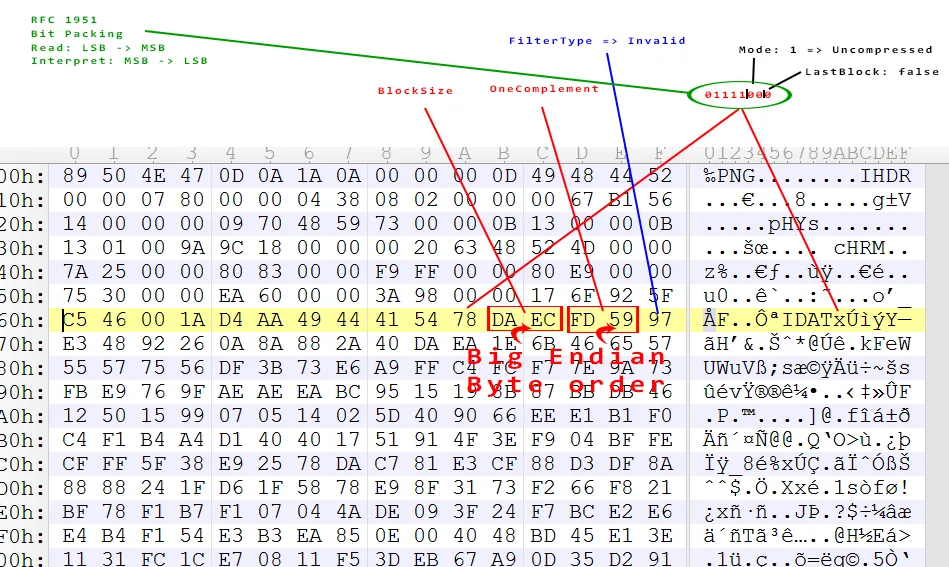
标准规定,在IDAT头之后,紧接着就是压缩数据。因此,由于数据是一个deflate流,所以在IDAT之后的第一个字符是0x78 == 01111000,这意味着一个模式一块(未压缩)且不是最终块。
奇怪的是 - 对我来说很难想象PNG编码器不使用动态哈夫曼编码来压缩过滤后的原始图像数据。deflate标准规定,在模式1中跳过当前字节的其余部分。
因此,接下来的四个字节表示未压缩块的大小及其补数。但0x59FD不是0xECDA的补数。即使我搞错了字节顺序:0xFD59也不是0xDAEC的补数。
嗯,下一个无用的字节就会出现。0x97被认为是未压缩但仍然经过滤波的原始png图像数据的第一个字节,因此必须是过滤器类型。但是0x97 == 10010111不是有效的过滤器类型。即使我搞错了位打包顺序11101001 == 0xe9也不是有效的过滤器类型。
我不再太关注RFC 1951,因为到目前为止,我能够使用我的deflate解压器实现所有类型的文件的解压缩,因此我怀疑我在PNG标准方面有所误解。
我一遍又一遍地阅读RFC 2083,但我看到的数据与RFC不匹配,这对我来说毫无意义,一定有一个缺失的部分!
当我查看以下字节时,实际上无法看到附近任何有效的过滤器类型字节,这使我认为经过过滤的png数据流仍然被压缩了。
如果从MSB到LSB读取0x78(IDAT之后的第一个字节),那么这将是有意义的,但RFC 1951表示相反。另一个想法(对我来说更有可能)是,在IDAT字符串和压缩的deflate流开始之间存在一些数据,但RFC 2083表示相反。布局很清晰。
4个字节大小 4个字节块名称(IDAT) [大小]字节(压缩的deflate流) 4个字节CRC校验和
因此,IDAT之后的第一个字节必须是压缩的deflate流的第一个字节 - 这表示模式1未压缩数据块。这意味着0x97必须是未压缩但经过滤波的png图像数据的第一个字节 - 这意味着0x97是第一行的过滤器类型 - 这是无效的...
我就是不明白,我是傻还是怎么了?
标准规定,在IDAT头之后,紧接着就是压缩数据。因此,由于数据是一个deflate流,所以在IDAT之后的第一个字符是0x78 == 01111000,这意味着一个模式一块(未压缩)且不是最终块。
奇怪的是 - 对我来说很难想象PNG编码器不使用动态哈夫曼编码来压缩过滤后的原始图像数据。deflate标准规定,在模式1中跳过当前字节的其余部分。
因此,接下来的四个字节表示未压缩块的大小及其补数。但0x59FD不是0xECDA的补数。即使我搞错了字节顺序:0xFD59也不是0xDAEC的补数。
嗯,下一个无用的字节就会出现。0x97被认为是未压缩但仍然经过滤波的原始png图像数据的第一个字节,因此必须是过滤器类型。但是0x97 == 10010111不是有效的过滤器类型。即使我搞错了位打包顺序11101001 == 0xe9也不是有效的过滤器类型。
我不再太关注RFC 1951,因为到目前为止,我能够使用我的deflate解压器实现所有类型的文件的解压缩,因此我怀疑我在PNG标准方面有所误解。
我一遍又一遍地阅读RFC 2083,但我看到的数据与RFC不匹配,这对我来说毫无意义,一定有一个缺失的部分!
当我查看以下字节时,实际上无法看到附近任何有效的过滤器类型字节,这使我认为经过过滤的png数据流仍然被压缩了。
如果从MSB到LSB读取0x78(IDAT之后的第一个字节),那么这将是有意义的,但RFC 1951表示相反。另一个想法(对我来说更有可能)是,在IDAT字符串和压缩的deflate流开始之间存在一些数据,但RFC 2083表示相反。布局很清晰。
4个字节大小 4个字节块名称(IDAT) [大小]字节(压缩的deflate流) 4个字节CRC校验和
因此,IDAT之后的第一个字节必须是压缩的deflate流的第一个字节 - 这表示模式1未压缩数据块。这意味着0x97必须是未压缩但经过滤波的png图像数据的第一个字节 - 这意味着0x97是第一行的过滤器类型 - 这是无效的...
我就是不明白,我是傻还是怎么了?
总结: 可能性1: 在IDAT和压缩deflate流有效开始之间存在其他数据,如果这些数据是真实的,则未在RFC2083或我所读过的任何关于图像压缩的书中提及。
可能性2: 数字0x78被解释为MSB -> LSB,这将表明是模式3块(动态霍夫曼编码),但这与RF1951相矛盾,后者对位打包非常清楚:(LSB -> MSB)
我已经知道了,缺失的部分一定是很愚蠢的东西,如果Stack Overflow只有一个删除按钮,我会感到非常紧急地需要出售我的灵魂 :-p