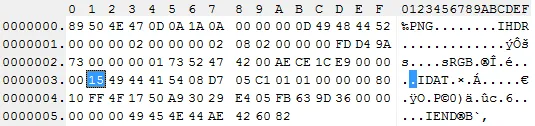
使用gzinflate函数,但跳过前两个字节和最后四个字节。
$contents = file_get_contents($in_filename);
$pos = 8;
$color_types = array('Greyscale','unknown','Truecolour','Indexed-color','Greyscale with alpha','unknown','Truecolor with alpha');
$len = strlen($contents);
$safety = 1000;
do {
list($unused,$chunk_len) = unpack('N', substr($contents,$pos,4));
$chunk_type = substr($contents,$pos+4,4);
$chunk_data = substr($contents,$pos+8,$chunk_len);
list($unused,$chunk_crc) = unpack('N', substr($contents,$pos+8+$chunk_len,4));
echo "chunk length:$chunk_len(dec) 0x" . sprintf('%08x',$chunk_len) . "h<br>\n";
echo "chunk crc :0x" . sprintf('%08x',$chunk_crc) . "h<br>\n";
echo "chunk type :$chunk_type<br>\n";
echo "chunk data $chunk_type bytes:<br>\n" . chunk_split(bin2hex($chunk_data)) . "<br>\n";
switch($chunk_type) {
case 'IHDR':
list($unused,$width,$height) = unpack('N2', substr($chunk_data,0,8));
list($unused,$depth,$Color_type,$Compression_method,$Filter_method,$Interlace_method) = unpack('C*', substr($chunk_data,8));
echo "Width:$width,Height:$height,depth:$depth,Color_type:$Color_type(" . $color_types[$Color_type] . "),Compression_method:$Compression_method,Filter_method:$Filter_method,Interlace_method:$Interlace_method<br>\n";
$bytes_per_pixel = $depth / 8;
break;
case 'PLTE':
$palette = array();
for($i=0;$i<$chunk_len;$i+=3) {
$tupl = bin2hex(substr($chunk_data,$i,3));
$palette[] = $tupl;
if($i && ($i % 30 == 0)) {
echo "<br>\n";
}
echo '<span style="color:' . $tupl . ';">[' . $tupl . ']</span>';
}
echo print_r($palette,true) . "<br>";
break;
case 'IDAT':
$compressed = substr($chunk_data,2,$chunk_len - 6);
$decompressed = gzinflate($compressed);
echo "decompressed chunk data " . strlen($decompressed) . " bytes:<br>\n" . chunk_split(bin2hex($decompressed),2 + $width * $bytes_per_pixel * 2) . "<br>\n";
for($row=0; $row<$height; $row++) {
for($col=1; $col<=$width; $col++) {
$index = (int)substr($decompressed,((int)$row*($width+1)+$col),1);
echo '<span style="color:' . $palette[$index] . ';">' . $index . '</span>';
}
echo "<br>\n";
}
break;
}
$pos += $chunk_len + 12;
echo "<hr>";
} while(($pos < $len) && --$safety);
 这是一个带有alpha通道的2×2像素真彩色图像(位深度为8)。
这是一个带有alpha通道的2×2像素真彩色图像(位深度为8)。