什么是依赖反转原则,为什么它很重要?
什么是依赖倒置原则,为什么它很重要?
224
- Phillip Wells
2
3参考 《依赖倒置原则》- Gabriel Schenker 发布:该原则指出,高层模块不应该依赖于底层模块,二者都应该依赖于其抽象(接口)。这意味着,无论是高层模块还是底层模块,都不应该直接依赖于具体实现细节。相反,它们应该依赖于抽象接口。在实践中,这意味着我们需要使用接口或抽象类来定义模块之间的通信协议,而不是使用具体实现类。这样做可以减少模块之间的耦合性,并支持更好的代码重用和可维护性。 - LCJ
14这里有太多使用维基百科的“高级”和“低级”术语的答案,这些术语难以理解,使得很多读者无法理解。如果你要复述维基百科,请在你的答案中定义这些术语以便让读者了解背景! - 8bitjunkie
16个回答
158
它是什么?
《敏捷软件开发》、《敏捷原则模式与实践》和《C#敏捷原则、模式与实践》这些书是深入理解依赖倒置原则背后最初的目标和动机的最佳资源。文章“依赖倒置原则”也是一个很好的资源,但由于它是草案的简化版本,最终进入了前面提到的书中,因此它遗漏了一些重要的讨论,涉及到包和接口所有权的概念,这些概念是区分这个原则与书籍《设计模式》(Gamma等人)中找到的更普遍的建议“编程到接口而不是实现”的关键。
总之,依赖倒置原则主要是为了将依赖项的传递方向从“高层”组件反转到“低层”组件,使得“低层”组件依赖于“高层”组件拥有的接口。(注意:这里的“高层”组件指需要外部依赖/服务的组件,不一定是它在分层架构中的概念位置。)通过这样做,耦合度不仅仅是减少,而是从理论上价值较低的组件转移到理论上更有价值的组件。
这是通过设计组件来实现的,其外部依赖项是以消费者提供的实现所需要的接口来表达的。换句话说,定义的接口表达了组件需要的内容,而不是你如何使用组件(例如“INeedSomething”而不是“IDoSomething”)。
依赖倒置原则不涉及抽象化依赖项的简单实践,例如通过接口的使用将依赖项抽象化(例如MyService →[ILogger ⇐ Logger])。虽然这将组件从依赖项的特定实现细节中解耦,但它并没有颠倒使用者和依赖项之间的关系(例如[MyService →IMyServiceLogger] ⇐ Logger)。
为什么它很重要?
依赖倒置原则的重要性可以归纳为一个目标:能够重用依赖于外部依赖项实现其功能的软件组件(如日志记录、验证等)。在这个通用的重用目标中,我们可以区分两种子类型的重用:
1. 在多个应用程序中使用具有子依赖项实现的软件组件(例如,您开发了一个 DI 容器并希望提供日志记录,但不想将您的容器耦合到特定的记录器中,以便每个使用您的容器的人都必须使用您选择的日志记录库)。 2. 在不断变化的上下文中使用软件组件(例如,您开发了业务逻辑组件,在应用程序的多个版本中保持相同,而实现细节正在演变)。
对于第一种情况,例如基础设施库中跨多个应用程序重用组件的情况,目标是为您的消费者提供核心基础设施需求,而不将消费者与您自己的库的子依赖关联起来,因为与这些依赖关联需要您的消费者也要求相同的依赖项。当您库的消费者选择使用不同的库满足同样的基础设施需求时(例如,NLog vs. log4net),或者选择使用所需库的后续版本,该版本与您的库所需版本不兼容时,这可能会出现问题。
对于第二种情况,在重用业务逻辑组件(即“高级组件”)方面,目标是将应用程序的核心领域实现与实现细节的不断变化(即变更/升级持久性库、消息库、加密策略等)隔离开来。理想情况下,更改应用程序的实现细节不应破坏封装应用程序业务逻辑的组件。
注意:有些人可能会反对将这种第二种情况描述为实际重用,认为在单个演进的应用程序中使用诸如业务逻辑组件之类的组件只代表一次使用。然而,这里的想法是,每次对应用程序的实现细节进行更改都会产生一个新的上下文和不同的用例,尽管最终的目标可以区分为隔离和可移植性。
虽然在第二种情况下遵循依赖倒置原则可以带来一些好处,但需要注意的是,对于像Java和C#这样的现代语言,其价值大大降低,甚至可能变得不相关。如前所述,DIP涉及将实现细节完全分离到单独的包中。然而,在不断发展的应用程序中,仅使用基于业务领域定义的接口将防止由于实现细节组件的不断变化而需要修改高层组件,即使实现细节最终驻留在同一个包中。该原则的此部分反映了原则制定时(即C ++)与语言相关的方面,但对于新语言并不相关。即便如此,依赖倒置原则的重要性主要在于可重复使用的软件组件/库的开发。
有关此原则如何与简单使用接口、依赖注入和分离接口模式相关的更长讨论可以在这里找到。此外,有关该原则如何与JavaScript等动态类型语言相关的讨论可以在这里找到。
- Derek Greer
24
17谢谢,我现在明白我的回答忽略了要点。 MyService → [ILogger ⇐ Logger] 和 [MyService → IMyServiceLogger] ⇐ Logger 之间的区别微妙而重要。 - Patrick McElhaney
3在同一条线上,这里有一个非常好的解释:http://lostechies.com/derickbailey/2011/09/22/dependency-injection-is-not-the-same-as-the-dependency-inversion-principle/。 - ejaenv
4@Casper Leon Nielsen - D.I.P.与D.I.无关。它们不是同义词,也不是等价概念。 - TSmith
5根据摘要段落所述,依赖倒置原则的重要性主要在于复用。如果John发布了一个具有对日志记录库的外部依赖关系的库,而Sam希望使用John的库,则Sam将承担短暂的日志记录依赖关系。Sam将无法在没有John选择的日志记录库的情况下部署应用程序。然而,如果John遵循DIP,Sam可以自由提供适配器并使用任何他选择的日志记录库。DIP不是关于方便,而是关于耦合度。 - Derek Greer
2通过箭头,我试图使用→和⇐分别近似表示UML类图的关联和泛化功能。方括号表明所涉及的类在同一个“包”中(例如,在.Net中的同一程序集中)。理解“包”的概念是谈论DIP时的一个关键区分概念。否则,您最终只会得到“按接口而非实现编程”的一般建议。 - Derek Greer
显示剩余19条评论
122
查看此文件:依赖倒置原则。
该原则基本上指出:
- 高层模块不应该依赖于低层模块。两者都应该依赖于抽象。
- 抽象不应该依赖于细节。细节应该依赖于抽象。
至于为什么这很重要,简而言之:更改是有风险的,通过依赖于一个概念而不是实现,您可以减少调用站点需要进行更改的程度。
有效地,DIP减少了不同代码段之间的耦合。其想法是,虽然有许多实现日志记录设施的方法,但您使用它的方式应该在时间上相对稳定。如果您可以提取代表日志记录概念的接口,则该接口应该比其实现更加稳定,并且调用站点应该受到维护或扩展该记录机制时所做更改的影响较小。
通过使实现也依赖于接口,您有可能在运行时选择更适合特定环境的实现。根据情况,这也可能很有趣。
- Carl Seleborg
12
34这个回答没有说明DIP为什么重要,甚至没有解释DIP是什么。
我已经阅读了官方的DIP文档,并认为这是一个非常糟糕且不合理的“原则”,因为它基于错误的假设:高层模块是可重用的。 - Rogério
3考虑一些对象的依赖图,应用 DIP(依赖反转原则)到这些对象上。现在任何一个对象都不依赖于其他对象的实现了。单元测试变得简单了。以后可以进行重构以实现重用。设计更改的影响范围非常有限。设计问题也不会扩散。另外请参考AI模式“黑板”来实现数据依赖反转。这是使得软件易于理解、易于维护和可靠的非常强大的工具。在此情境中请忽略依赖注入,因为它并不相关。 - Tim Williscroft
6使用类B的类A并不意味着A“依赖”于B的实现;它仅依赖于B的公共接口。添加一个独立的抽象层,使A和B都依赖于它,只意味着A不再在编译时依赖于B的公共接口。可以轻松地实现单元之间的隔离,无需这些额外的抽象。在Java和.NET中有特定的模拟工具来处理所有情况(如静态方法、构造函数等)。应用DIP往往会使软件更加复杂、难以维护,并且没有更多可测试性。 - Rogério
2@Rogerio,请看下面Derek Greer的回复,他解释了这个问题。据我所知,DIP认为是A规定自己需要什么,而不是B说A需要什么。因此,A需要的接口不应该由B提供,而是由A自己提供。 - ejaenv
1一个例子会更好。 - Juzer Ali
显示剩余7条评论
18
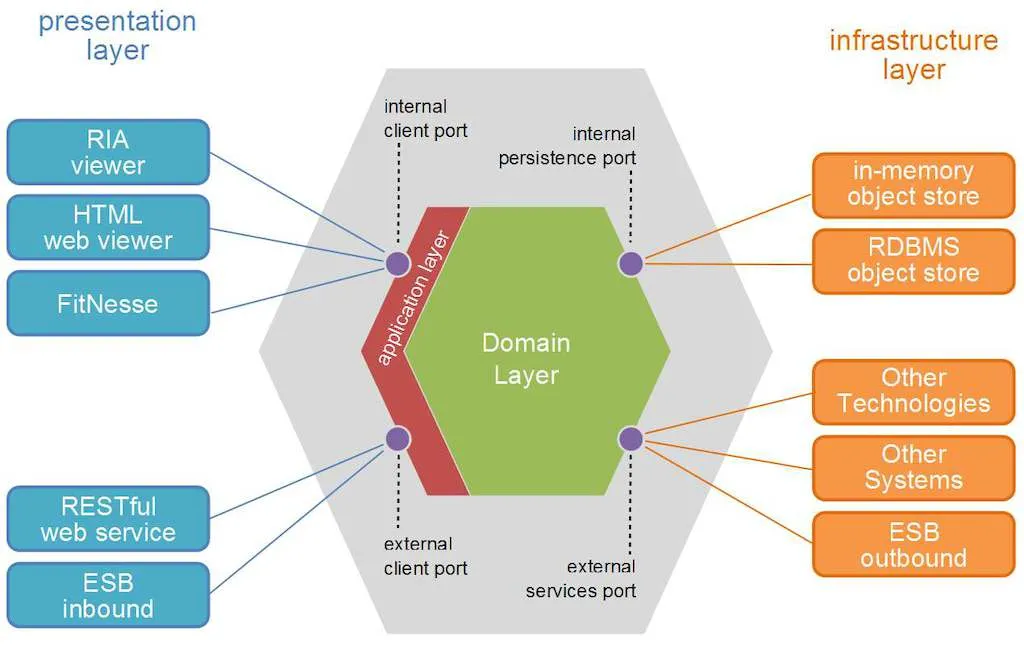
依赖倒置原则的良好应用可以在整个应用程序架构层面上提供灵活性和稳定性。它将使您的应用程序更加安全和稳定。
传统的分层架构通常是基于用户界面层依赖于业务层,而业务层又依赖于数据访问层。
我们将为数据访问层创建一个库或包。
另外一个库或包层的业务逻辑,依赖于数据访问层。
首先定义领域层和其通信抽象,即定义持久化。
(来源: pragprog.com)
传统的分层架构通常是基于用户界面层依赖于业务层,而业务层又依赖于数据访问层。
我们将为数据访问层创建一个库或包。
// DataAccessLayer.dll
public class ProductDAO {
}
另外一个库或包层的业务逻辑,依赖于数据访问层。
// BusinessLogicLayer.dll
using DataAccessLayer;
public class ProductBO {
private ProductDAO productDAO;
}
带有依赖反转的分层架构
依赖反转指出以下内容:
高级模块不应该依赖低级模块。两者都应该依赖于抽象。
抽象不应该依赖于细节。细节应该依赖于抽象。
什么是高级模块和低级模块?考虑到模块例如库或包,高级模块通常具有依赖性,而低级模块则是它们所依赖的模块。
换句话说,高级模块将调用操作,而低级模块将执行操作。
从这个原则得出的一个合理结论是,没有具体实现之间的依赖关系,但必须依赖于一个抽象。但是根据我们采取的方法,我们可能会误用依赖关系,而是使用一个抽象。
想象一下我们如何调整代码:
我们将为数据访问层定义一个库或包,其中定义了抽象。
// DataAccessLayer.dll
public interface IProductDAO
public class ProductDAO : IProductDAO{
}
还有另一个库或包层的业务逻辑,它依赖于数据访问层。
// BusinessLogicLayer.dll
using DataAccessLayer;
public class ProductBO {
private IProductDAO productDAO;
}
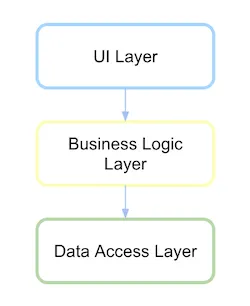
尽管我们依赖于业务和数据访问之间的抽象依赖关系,但它们之间的联系仍然保持不变。
首先定义领域层和其通信抽象,即定义持久化。
// Domain.dll
public interface IProductRepository;
using DataAccessLayer;
public class ProductBO {
private IProductRepository productRepository;
}
当持久层依赖于域时,如果定义了依赖项,则现在需要反转。
// Persistence.dll
public class ProductDAO : IProductRepository{
}
(来源: xurxodev.com)
{kind=link}
深入理解原则
重要的是要充分吸收这个概念,加深其目的和好处。如果我们只停留在机械地学习典型案例库中,就无法确定我们可以在哪里应用依赖原则。
但是为什么要反转依赖关系?除了具体的例子之外,主要目标是什么?
这通常允许最稳定的事物(不依赖于不稳定的事物)更频繁地发生变化。
更改持久性类型(数据库或访问同一数据库的技术)比更改与持久性通信的域逻辑或操作更容易。因此,依赖关系被反转,因为如果发生这种变化,更改持久性将更容易。这样,我们就不必更改域。域层是最稳定的,因此不应依赖任何东西。
除了这个存储库示例之外,还有许多场景适用于这个原则,并且有基于这个原则的架构。
架构
有些架构中,依赖反转是定义的关键。在所有领域中,抽象是最重要的,它们将指示域与其余包或库之间的通信协议。
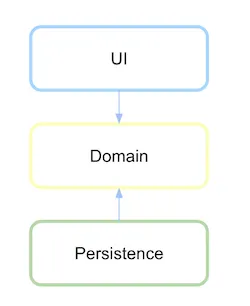
干净架构
在干净架构中,域位于中心,如果您朝着表示依赖关系的箭头方向看,就清楚了哪些层最重要和稳定。外部层被认为是不稳定的工具,因此应避免依赖它们。
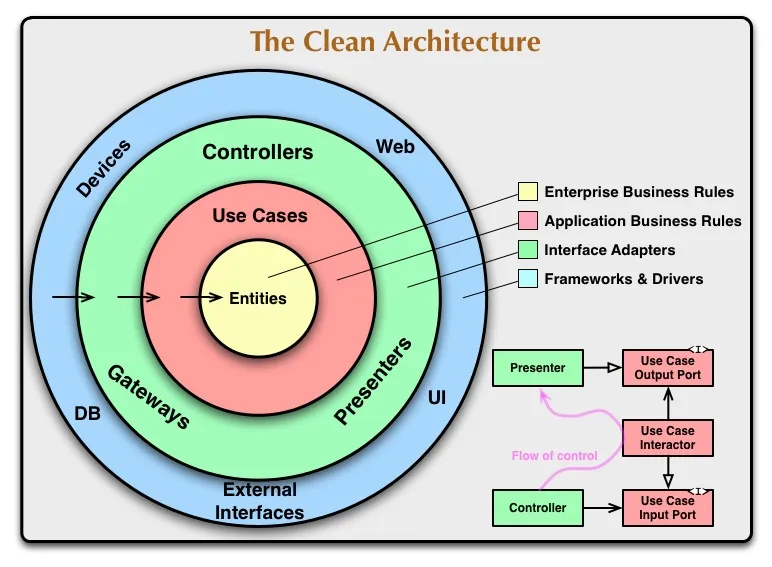
(来源:8thlight.com)
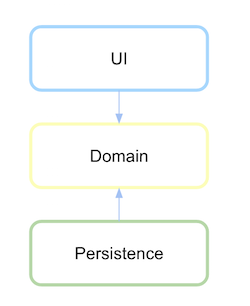
六边形架构
同样的情况也发生在六边形架构中,其中领域也位于中心部分,端口是从领域向外通信的抽象。在这里,再次显而易见的是,领域是最稳定和传统的依赖关系被倒置了。(来源: pragprog.com)
{kind=link}
- xurxodev
1
2我不确定它想要表达什么,但这个句子是不连贯的:“但根据我们采取的方法,我们可能会错误地应用投资依赖性,但是一个抽象概念。”也许你想修复一下? - Mark Amery
17
当我们设计软件应用程序时,可以将低级类视为实现基本和主要操作(磁盘访问、网络协议等)的类,将高级类视为封装复杂逻辑(业务流程等)的类。
后者依赖于低级类。一种自然的实现方式是先编写低级类,然后再编写复杂的高级类。由于高级类是根据其他类定义的,因此这似乎是合乎逻辑的方法。但这不是一种灵活的设计。如果我们需要替换低级类会发生什么呢?
依赖倒置原则规定:
- 高层模块不应该依赖低层模块。两者都应该依赖于抽象。
- 抽象不应该依赖于细节。细节应该依赖于抽象。
该原则旨在“颠覆”软件中高级模块应该依赖于低级模块的传统概念。在这里,高级模块拥有抽象(例如,决定接口方法),这些抽象由低级模块实现。从而使低级模块依赖于高级模块。
- nikhil.singhal
11
基本上,它的意思是:
类应该依赖于抽象(例如接口、抽象类),而不是具体细节(实现)。
- martin.ra
2
这真的那么简单吗?正如DerekGreer所提到的,有长篇文章甚至书籍?我实际上正在寻找简单的答案,但如果它真的那么简单,那就令人难以置信 :D - Dariux
1@darius-v,这不是“使用抽象”的另一种说法。它关于谁拥有接口。原则是客户端(高层组件)应该定义接口,而低层组件应该实现它们。 - ekim boran
10
对我而言,依赖倒置原则(Dependency Inversion Principle)在官方文章中的描述实际上是一种误导性的尝试,旨在增加本质上不太可重用的模块的可重用性,并解决C++语言中的一个问题。
C++中存在的问题是头文件通常包含私有字段和方法的声明。因此,如果高级C ++模块包含低级模块的头文件,则它将依赖于该模块的实际实现细节。显然,这不是一件好事。但这在今天常用的更现代的语言中并不是问题。
高级模块本质上比低级模块不太可重用,因为前者通常比后者更应用/上下文特定。例如,实现UI屏幕的组件是最高级别的,也非常(完全?)特定于应用程序。试图在不同的应用程序中重用这样的组件是适得其反的,并且只会导致过度设计。
因此,在与组件B(不依赖于A)相关的同一级别上创建一个单独的抽象仅在组件A真正有用于在不同的应用程序或上下文中重用时才能完成。如果不是这种情况,则应用DIP将是不良的设计。
C++中存在的问题是头文件通常包含私有字段和方法的声明。因此,如果高级C ++模块包含低级模块的头文件,则它将依赖于该模块的实际实现细节。显然,这不是一件好事。但这在今天常用的更现代的语言中并不是问题。
高级模块本质上比低级模块不太可重用,因为前者通常比后者更应用/上下文特定。例如,实现UI屏幕的组件是最高级别的,也非常(完全?)特定于应用程序。试图在不同的应用程序中重用这样的组件是适得其反的,并且只会导致过度设计。
因此,在与组件B(不依赖于A)相关的同一级别上创建一个单独的抽象仅在组件A真正有用于在不同的应用程序或上下文中重用时才能完成。如果不是这种情况,则应用DIP将是不良的设计。
- Rogério
9
3DIP对于所有语言都很重要,与C++本身无关。即使您的高级代码永远不会离开应用程序,DIP也可以在添加或更改低级代码时限制代码更改。这降低了维护成本和变更的意外后果。DIP是一个更高级别的概念。如果您不理解它,需要进行更多的搜索。 - Dirk Bester
3我认为你误解了我关于C ++的陈述。那只是对DIP的一种激励,毫无疑问它比那更通用。请注意,DIP的官方文章明确指出其核心动机是支持高级模块的重用,使其免受低级模块更改的影响;如果没有重用的需要,则很可能过度设计和过度工程化。(你读过它吗?它还谈到了C ++问题。) - Rogério
1你难道没有考虑到DIP的反向应用吗?也就是说,更高级别的模块实现了你的应用程序。你的主要关注点不是重用它,而是使它不那么依赖于较低级别模块的实现,以便将来更新它以跟上变化的步伐,从而使你的应用程序免受时间和新技术的摧残。这并不是为了更容易替换WindowsOS,而是为了使WindowsOS不那么依赖于FAT/HDD的实现细节,以便新的NTFS/SSD可以插入WindowsOS而没有或很少的影响。 - knockNrod
@knockNrod 我明白你的意思,但那不是DIP。在DIP中,由低级组件实现的接口在与使用该接口的高级(和特定于应用程序的)组件相同级别上定义。在您描述的情况下,此接口将在中间级别上定义,其中高级组件对其具有非反转依赖关系。一个具体的例子是使用JPA接口的业务应用程序,该接口由Hibernate实现;在这三个级别之间,没有依赖倒置。 - Rogério
1UI界面绝对不是最高级别的模块,也不应该成为任何应用程序的最高级别模块。最高级别的模块是包含业务规则的模块。最高级别的模块也不是由其可重用性潜力来定义的。请查看Uncle Bob在这篇文章中的简单解释:http://blog.cleancoder.com/uncle-bob/2016/01/04/ALittleArchitecture.html - humbaba
显示剩余4条评论
7
依赖倒置原则的更加明确的表述应该是:
封装复杂业务逻辑的模块不应直接依赖于封装业务逻辑的其他模块,而是应该仅依赖于简单数据的接口。
即,不要像人们通常所做的那样实现类Logic:
class Dependency { ... }
class Logic {
private Dependency dep;
int doSomething() {
// Business logic using dep here
}
}
您应该像这样做:
class Dependency { ... }
interface Data { ... }
class DataFromDependency implements Data {
private Dependency dep;
...
}
class Logic {
int doSomething(Data data) {
// compute something with data
}
}
Data和DataFromDependency应该与Logic在同一个模块中,而不是与Dependency在一起。
为什么这样做呢?
- 现在两个业务逻辑模块已经解耦。当
Dependency发生变化时,您不需要更改Logic。 - 理解
Logic的功能变得更加简单:它只对看起来像ADT的内容进行操作。 Logic现在可以更容易地进行测试。您现在可以直接使用虚假数据实例化Data并传递它。无需使用模拟对象或复杂的测试脚手架。
- mattvonb
2
1我认为这不对。如果
DataFromDependency直接引用Dependency,并且在同一个模块中作为Logic,那么Logic模块仍然在编译时直接依赖于Dependency模块。根据Uncle Bob解释的原则,避免这种情况正是DIP的全部意义。相反,为了遵循DIP,Data应该与Logic在同一个模块中,但DataFromDependency应该与Dependency在同一个模块中。 - Mark Amery也许
DataFromDependency 和 Data 应该确实定义在与 Logic 不同的模块中,但它们绝对不应该放在与 Dependency 相同的模块中。这通常是不可能的,例如当 Dependency 来自外部库时。 - mattvonb6
其他人在这里已经给出了好的答案和范例。
依赖倒置原则(DIP)之所以重要,是因为它确保了面向对象编程中的“松耦合设计”原则。
您的软件中的对象不应该形成层次结构,其中一些对象是依赖于低级对象的顶级对象。低级对象的更改将会传递到顶级对象,这会使软件非常脆弱,难以进行更改。
您希望您的“顶级”对象非常稳定,不易受到更改的影响,因此需要反转依赖关系。
- Hace
1
6DIP在Java或.NET代码中是如何实现的呢?与C++不同,低级模块的实现更改不需要更改使用它的高级模块。只有公共接口的更改会产生连锁反应,但此时在较高级别定义的抽象也必须更改。 - Rogério
4
依赖倒置原则(DIP)
DIP是SOLID原则的一部分[关于],也是面向对象设计(OOD)的一部分,由Uncle Bob提出。它主要关注类(layer...)之间的松耦合。类不应该依赖于具体实现,而应该依赖于抽象/接口
问题:
//A -> B
class A {
B b
func foo() {
b = B();
}
}
解决方案:
//A -> IB <|- B
//client[A -> IB] <|- B is the Inversion
class A {
IB ib // An abstraction between High level module A and low level module B
func foo() {
ib = B()
}
}
现在A不再依赖于B(一对一),现在A依赖于接口IB,这个接口由B实现,这意味着A依赖于IB的多个实现(一对多)
- yoAlex5
4
控制反转(IoC)是一种设计模式,其中对象通过外部框架获取其依赖项,而不是向框架请求其依赖项。
使用传统查找的伪代码示例:
class Service {
Database database;
init() {
database = FrameworkSingleton.getService("database");
}
}
使用IoC的相似代码:
class Service {
Database database;
init(database) {
this.database = database;
}
}
控制反转(IoC)的好处包括:
- 您不依赖于中央框架,因此可以根据需要进行更改。
- 由于对象是通过注入创建的,最好使用接口,因此很容易创建单元测试,将依赖关系替换为模拟版本。
- 解耦代码。
- Staale
5
1依赖倒置原则(Dependency Inversion Principle)和控制反转(Inversion of Control)是相同的吗? - Peter Mortensen
3DIP中的“反转”与控制反转中的“反转”不同。第一个是关于编译时依赖,而第二个是关于运行时方法之间的控制流。 - Rogério
我觉得IoC版本缺少了一些东西。它如何定义数据库对象,它从哪里来?我试图理解这不仅仅是将所有依赖项延迟到巨大的上层依赖项中。 - Richard Tingle
2正如@Rogério所说,DIP不是DI/IoC。在我看来,这个答案是错误的。 - zeraDev
@RichardTingle 大量的依赖项复数。
我认为这没有任何问题。当你阅读代码时,它更清晰、更直接地为你总结了所有内容,而不是必须在混乱的路径中挖掘整个代码来发现一个独立变量。 - ahnbizcad
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接