module Has (r,p,s) where
import Prelude ((==),Bool(..),otherwise,(||),Eq)
import qualified Data.List as L
filter :: (a -> Bool) -> [a] -> [a]
filter _pred [] = []
filter pred (x:xs)
| pred x = x : filter pred xs
| otherwise = filter pred xs
问题1:这个
filter函数是从GHC的库中复制过来的,但是为什么它与直接导入的filter相比会消耗越来越多的内存,而直接导入的filter只会消耗恒定数量的内存。elem :: (Eq a) => a -> [a] -> Bool
elem _ [] = False
elem x (y:ys) = x==y || elem x ys
问题2:这个
filter函数是从GHC库中复制的,但为什么它会像直接使用的elem一样消耗越来越多的内存,而与直接导入的filter相比则消耗越来越多的内存。r = L.filter (==1000000000000) [0..]
p = filter (==1000000000000) [0..]
s = 1000000000000 `elem` [0..]
GHC版本: 7.4.2 操作系统: Ubuntu 12.10 编译时使用 -O2 进行了优化。
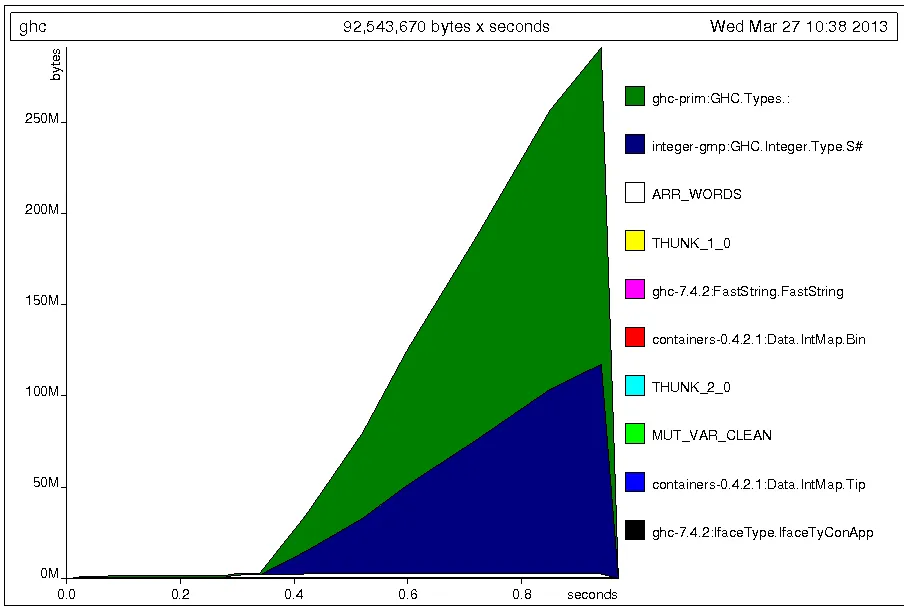
正如上述 filter 和 elem 的定义暗示的那样,p = filter (==1000000000000) [0..] 和 s = 1000000000000 `elem` [0..] 中的 [0..] 应该逐渐被垃圾回收。但是,p 和 s 却消耗着越来越多的内存。而直接导入 filter 定义的 r 则消耗着恒定的内存。
我的问题是,为什么 GHC 中直接导入的函数与我从 GHC 库中复制源代码编写的函数有这么大的差别。我想知道 GHC 是否出了什么问题。
我还有一个进一步的问题:上面的代码摘自我编写的一个项目,该项目也面临“理论上应该被垃圾回收的内存消耗增长”的问题。所以我想知道在 GHC 中有没有一种方法可以找到哪个变量占用了如此多的内存。
感谢您的阅读。
elem时的内存增长。 - Koterpillar{-# RULES "filter" [~1] forall p xs. filter p xs = build (\c n -> foldr (filterFB c p) n xs) #-},这意味着你引用的定义通常不会被使用。 - 话虽如此,我也无法重现您的内存消耗问题。您使用了什么优化标志? - leftaroundabout[0..]是否为r、p和s新计算的;还是以某种方式共享(作为顶级定义或作为函数的参数?)我想我们需要看到更多您的代码…… - yatima2975-O2编译的,但当你在 ghci 中运行时,内存消耗增加了,对吧? - Daniel Fischer