第一定义中,x如何变成表示修复 x?
fix f = let x = f x in x
Haskell中的let绑定是递归的
首先,需要意识到Haskell允许递归的let绑定。在一些其他编程语言中所谓的“let”被称为“letrec”。这在函数定义中感觉相当正常。例如:
ghci> let fac n = if n == 0 then 1 else n * fac (n - 1) in fac 5
120
然而,对于值的定义来说,这可能看起来相当奇怪。尽管如此,由于Haskell的非严格性,值可以进行递归定义。
ghci> take 5 (let ones = 1 : ones in ones)
[1,1,1,1,1]
请参考
Haskell入门教程第3.3和3.4节,了解更多有关Haskell的惰性计算的详细信息。
在GHC中,一个尚未求值的表达式被包装在一个“thunk”中:一种执行计算的承诺。只有在必须时才会评估thunk。假设我们想要
fix someFunction。根据
fix的定义,这是一个thunk。
let x = someFunction x in x
现在,GHC看到的是类似于这样的东西。
let x = MAKE A THUNK in x
因此,它会为您愉快地创建一个惰性计算并继续执行,直到您要求知道 x 实际上是什么。
示例评估
该惰性计算的表达式恰好是指向自身的。让我们以使用 fix 的 ones 示例进行重写。
ghci> take 5 (let ones recur = 1 : recur in fix ones)
[1,1,1,1,1]
那么这个thunk会是什么样子呢?
为了更清晰地展示,我们可以将“ones”作为匿名函数“\recur -> 1 : recur”内联。
take 5 (fix (\recur -> 1 : recur))
take 5 (let x = (\recur -> 1 : recur) x in x)
那么,x是什么呢?虽然我们不太确定x是什么,但我们仍然可以进行函数应用:
take 5 (let x = 1 : x in x)
嘿,看这里,我们回到了之前的定义。
take 5 (let ones = 1 : ones in ones)
如果你认为你理解了那个的工作原理,那么你就能很好地理解fix的工作原理。
使用第一个定义是否有任何优势?
是的。问题在于即使进行了优化,第二个版本也可能会导致空间泄漏。请参见GHC trac ticket #5205,关于forever定义的类似问题。这就是为什么我提到thunks:因为let x = f x in x只分配了一个thunk:即x thunk。
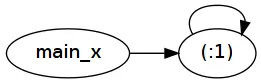
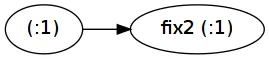
fix1(1:) !! 1000000和fix2(1:) !! 1000000。 - is7s