我试图理解数据库索引在大O符号表示法方面的性能。在不了解太多的情况下,我猜测:
- 在主键或唯一索引上查询将给您提供O(1)的查找时间。
- 在非唯一索引上查询也将提供O(1)的时间,尽管“1”可能比唯一索引慢(?)
- 在没有索引的列上查询将给出O(N)的查找时间(完整表扫描)。
这个概括正确吗?在主键上查询会比O(1)的性能更差吗?我的具体关注点是SQLite,但我很想知道这在不同数据库之间的差异程度。
大多数关系型数据库将索引构造为B-trees(即B树)。
如果一个表有聚集索引,那么数据页将作为B-tree的叶节点存储。实际上,聚集索引就成了整个表。
对于没有聚集索引的表,表中的数据页将按堆积方式存储。任何非聚集索引都是B-trees,其中B-tree的叶节点标识着堆积中的特定页面。
B-tree的最坏情况高度为O(log n),由于搜索取决于高度,因此B-tree查找大体上运行在
O(logt n)
的时间复杂度,其中t是最小化因子(每个节点必须至少有t-1个键,最多有2*t* -1个键(例如2*t*个子节点)。
这是我理解的方式。
当然,不同的数据库系统可能会使用不同的数据结构。
如果查询不使用索引,则搜索是迭代遍历包含数据页的堆或B-tree。
如果使用的索引可以满足查询条件,则搜索会更快;否则,需要查找相应的数据页以从内存中获取数据。
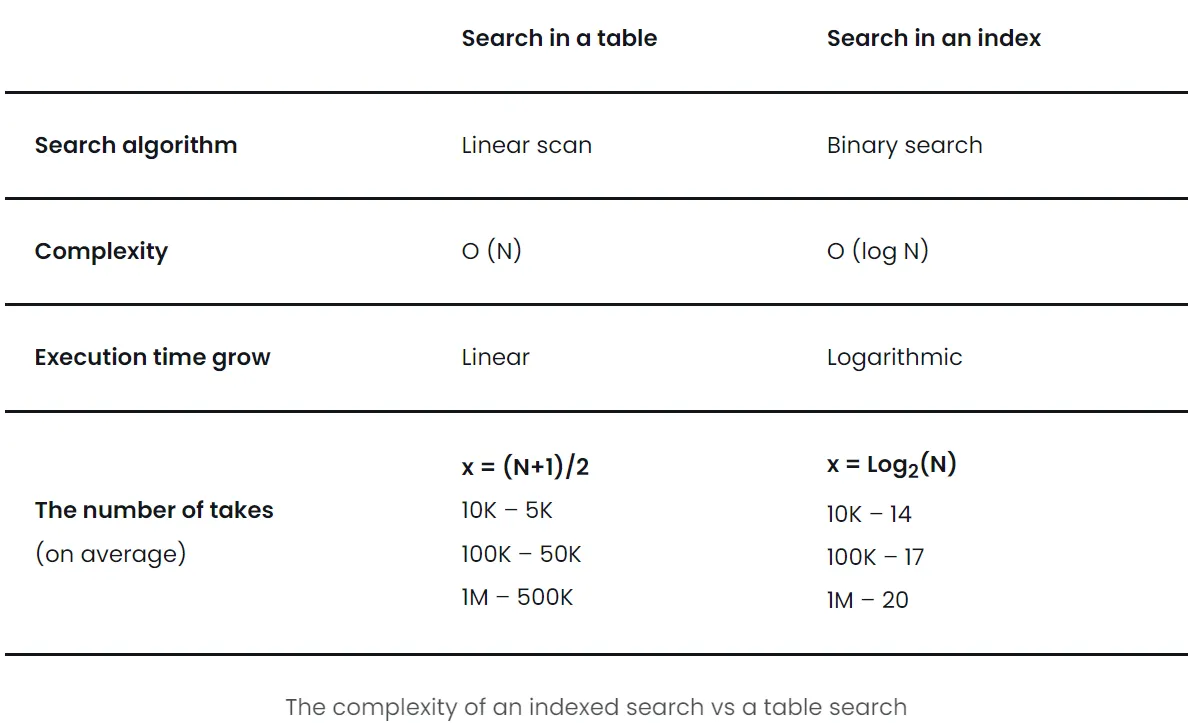
索引查询(无论是否唯一)通常是O(log n)。 简单地说,您可以将其视为在排序数组中执行二进制搜索类似。更准确地说,这取决于索引类型。 但是,例如B树搜索仍然是O(log n)。
如果没有索引,则确实为O(N)。
其他答案已经给出了一个很好的起点;但我想补充的是,要达到O(1),主索引本身需要基于哈希(这通常不是默认选择);因此更常见的是对数时间复杂度(B树)。
您说的二级索引通常具有相同的复杂度,但实际性能更差--这是因为索引和数据没有聚集在一起,所以常数(磁盘寻道次数)更大。
这取决于您的查询是什么。
Column = Value的条件允许使用基于哈希的索引,具有O(1)的查找时间。然而,许多数据库,包括SQLite,不支持它们。<,>,<=,>=)的条件可以利用有序索引,通常使用二叉树实现,具有O(log n)的查找时间。由于您主要关注SQLite,您可能需要阅读其查询优化器概述,其中更详细地解释了如何选择索引。