我需要通过集合的交集来联合一组集合,并编写一个具有这种签名的函数。
这里是集合的简单示例。
在这个例子中,我们可以看到集合
我不知道从哪里开始解决这个任务。
Collection<Set<Integer>> filter(Collection<Set<Integer>> collection);
这里是集合的简单示例。
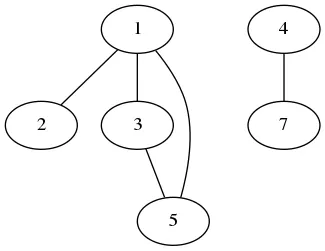
1) {1,2,3}
2) {4}
3) {1,5}
4) {4,7}
5) {3,5}
在这个例子中,我们可以看到集合
1、3和5相交。我们可以将它重写为一个新的集合{1,2,3,5}。另外,我们还有两个带有交集的集合,它们是2和4,我们可以创建一个新的集合{4,7}。输出结果将是两个集合的集合:{1,2,3,5}和{4,7}。我不知道从哪里开始解决这个任务。
{1,2,3,5}和{4,7})。 - MarkgroupBy。 - Mark