虽然我试图理解CAP中的“可用性”(A)和“分区容错性”(P),但我发现很难理解各种文章中的解释。
我有一种感觉,即A和P可以一起实现(我知道这不是真的,这就是我无法理解的原因!)。
简单地解释一下,A和P分别是什么以及它们之间的区别是什么?
我有一种感觉,即A和P可以一起实现(我知道这不是真的,这就是我无法理解的原因!)。
简单地解释一下,A和P分别是什么以及它们之间的区别是什么?
一致性指的是数据在整个集群中是相同的,因此您可以从/向任何节点进行读取或写入,并获得相同的数据。
可用性意味着即使集群中的某个节点关闭,也能访问该集群。
分区容错意味着即使两个节点之间存在“分区”(通信中断),集群仍将继续运行(两个节点均正常,但无法通信)。
为了同时实现可用性和分区容错,您必须放弃一致性。考虑如果您有两个节点X和Y处于主-主设置中。现在,X和Y之间的网络通信中断,因此它们无法同步更新。此时你可以:
A)允许节点不同步(放弃一致性),或
B)认为集群“宕机”(放弃可用性)
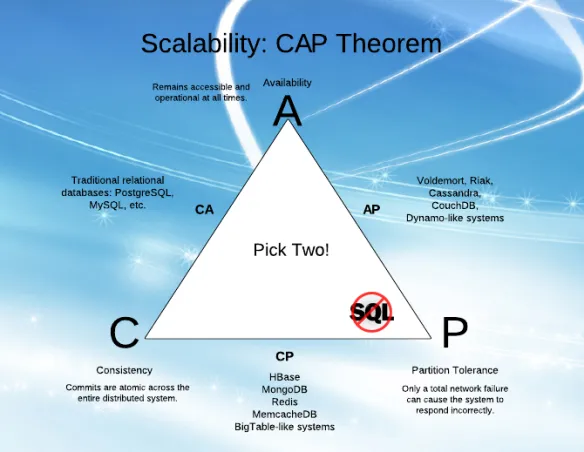
所有可用的组合方式如下:
需要注意的是, CA系统实际上不存在(即使某些系统声称如此)。
考虑将P与C和A平等对待是一个错误,而在C、A、P之间的“三选二”概念是误导性的。我会简洁地解释CAP定理:“在分布式数据存储中,在网络分区时,您必须选择一致性或可用性,无法同时获得两者。” 新的NoSQL系统试图专注于可用性,而传统的ACID数据库更加注重一致性。
你真的不能选择CA,网络分区并不是任何人都想要的,它只是分布式系统中不可避免的现实,网络可能会出现故障。问题是当这种情况发生时,您选择什么样的权衡来适应您的应用程序。这篇文章来自首次提出该术语的人,似乎非常清楚地解释了这一点。
以下是我对CAP的讨论,特别是P方面的解释。
只有在使用单个服务器数据库时(可能具有复制功能,但所有数据都位于一个"故障块"上-不考虑部分故障),才能实现CA。
如果您的问题需要扩展、分布式和多服务器-网络分区可能会发生。您已经需要P了。我解决的问题中很少适用于单服务器始终范例(或者如Stonebraker所说,“分布式是桌子上的筹码”)。如果您可以找到一个CA问题,像传统的非规模化RDBMS这样的解决方案提供了很多好处。
对我来说,这种情况比较少:所以我们继续讨论AP与CP。
只有在存在分区时,您才会选择AP和CP操作。如果网络&硬件正常运行,您就可以得到您想要的结果。
让我们讨论AP / CP区别。
AP-当存在网络分区时,让独立部分自由操作。
CP-当存在网络分区时,关闭节点或禁止读写,以便出现确定性故障。
我喜欢既能做AP又能做CP的架构,因为某些问题是AP,某些问题是CP-有些数据库都可以同时做到。在CP和AP解决方案中,也存在一些微妙的差别。
例如,在AP数据集中,您可能会出现不一致的读取和生成写入冲突的可能性-这些是两种不同的AP模式。您的系统能否配置为高读可用性但禁止写入冲突的AP?或者您的AP系统可以接受写入冲突,并具有强大而灵活的解决方案?最终您需要两者都吗,还是选择只有一个系统?
在CP系统中,如果存在小型分区(单个服务器),则会出现多少不可用性(如果有)?更高的复制可以增加CP系统的不可用性,系统如何处理这些权衡?
这些都是CP与AP问题要问的问题。
Brewer的“12年后”文章是目前这个领域的一篇很好的阅读材料。我相信这篇文章用清晰的语言推进了CAP辩论,强烈推荐阅读。
读取操作保证会返回给定客户端最近的写入结果(类似 ACID)。如果在此期间有任何请求,则必须等待数据在节点间完成同步。
每个节点(如果没有失败)始终执行查询并应始终响应请求。无论它是否返回最新副本。
当发生网络分区时,系统将继续运行。
关于AP,可用性(始终可访问)可以与分区容错性相关联(Cassendra)或不相关联(RDBMS)。
我查阅了很多链接,但除了一个之外,没有一个能给我满意的答案。
因此,我用非常简单的语言描述CAP。
一致性:无论数据来自哪个节点,都必须返回相同的数据。
可用性:节点应该有响应(必须可用)。
分区容错性:集群应该有响应(必须可用),即使节点之间存在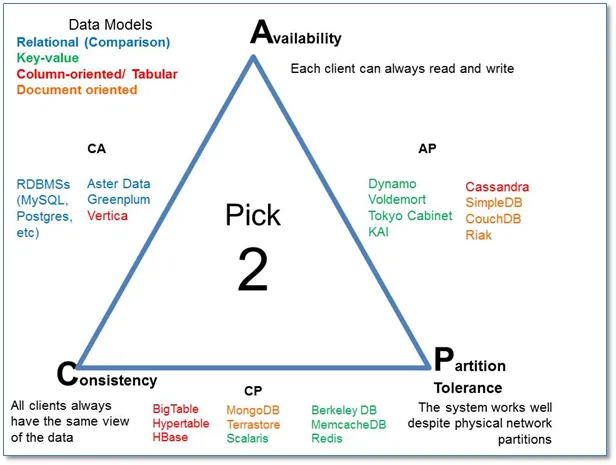 分区(即网络故障)。
(它更加令人困惑的一个主要原因是其糟糕的命名约定。如果我有权利,我可能会提供DNC定理代替:即数据一致性、节点可用性和集群可用性分别对应一致性、可用性和分区容错性)。
分区(即网络故障)。
(它更加令人困惑的一个主要原因是其糟糕的命名约定。如果我有权利,我可能会提供DNC定理代替:即数据一致性、节点可用性和集群可用性分别对应一致性、可用性和分区容错性)。
CP数据库: CP数据库提供了一致性和分区容错性,但以可用性为代价。当任何两个节点之间发生分区时,系统必须关闭非一致性节点(即使其变得不可用)直到分区解决。
AP数据库: AP数据库通过牺牲一致性来实现可用性和分区容错性。当发生分区时,所有节点仍然可用,但在错误的分区端的节点可能会返回比其他节点旧的数据版本。(当解决分区时,AP数据库通常重新同步节点以修复系统中的所有不一致性。) CA数据库: CA数据库在所有节点之间提供一致性和可用性。然而,如果系统中任意两个节点之间存在分区,则无法实现这一点,也因此无法提供容错性。在分布式系统中,无法避免分区的发生。因此,虽然我们可以在理论上讨论CA分布式数据库,但在实际应用中,一个CA分布式数据库是存在但不应该存在的。来源: 了不起的Martin kleppmann的 作品
举个例子: Cassandra最多只能成为AP系统。但是如果您将其配置为基于Quorum进行读取或写入,则它不再符合CAP定理的定义,仅是P系统。
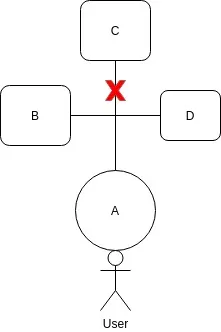
So the system has Partition-Tolerance and consistency (P,C).
But no availability, because of the rejection.
So the system has Partition-Tolerance and availability (P,A).
But no consistency.because C has not updated.
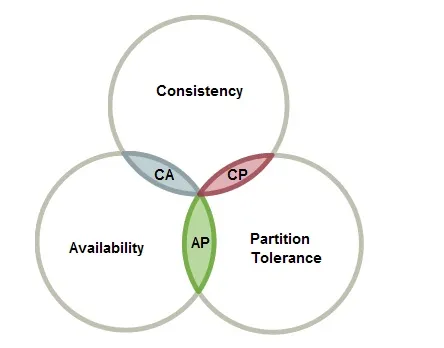
一致性
每个节点在同一时间包含相同的数据。
可用性
至少有一个节点必须始终可用以提供数据。
分区容错性
系统故障非常罕见。
大多数系统只能保证最少两种特性,即CA、AP或CP。