在这里有一个非常棒的讲座,讲的是使用Kingsby的Jesper库模拟Cassandra中的分区问题。
我的问题是——在Cassandra中,你主要关注CAP定理中的分区部分,还是需要管理一致性因素?
在这里有一个非常棒的讲座,讲的是使用Kingsby的Jesper库模拟Cassandra中的分区问题。
我的问题是——在Cassandra中,你主要关注CAP定理中的分区部分,还是需要管理一致性因素?
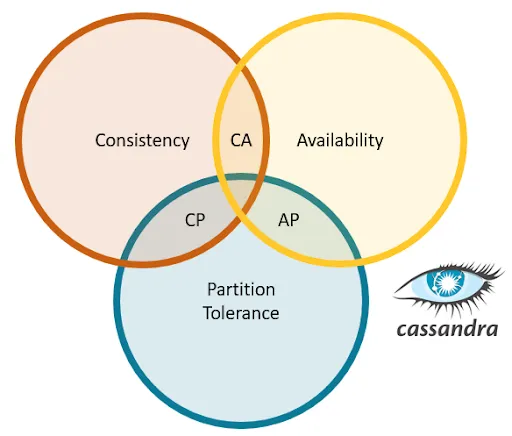
Cassandra通常被归类为AP系统,这意味着可用性和分区容忍性通常被认为比一致性更重要。然而,现实世界的系统很少完全符合这些类别,所以更有帮助的是将CAP视为一个连续体。大多数系统都会做出一些努力来保持一致性、可用性和分区容忍性,包括Cassandra在内的许多系统可以根据最重要的内容进行调整。像复制因子和一致性级别之类的旋钮可以对C、A和P产生巨大影响。
即使定义这些术语的含义也可能具有挑战性,因为各种用例对每个要求都有不同的要求。因此,与其将系统分类为CP、AP或其他什么,不如考虑其提供的选项,针对特定用例调整这些属性才更有帮助。
这里有一个有趣的讨论,介绍了自CAP定理首次引入以来的变化。
CAP代表一致性(Consistency)、可用性(Availability)和分区容错性(Partition Tolerance)。
一般来说,在任意给定点上,分布式系统不可能保证以上三点。Apache Cassandra属于AP系统,这意味着Cassandra对可用性和分区容错性是正确的,但对一致性来说并不是这样,但是可以通过复制因子(数据副本数)和一致性级别(读写)来进一步调整。
了解更多信息,请参阅:https://docs.datastax.com/en/cassandra/3.0/cassandra/dml/dmlConfigConsistency.html
Cassandra原本的设计是为高可用性而生的,但你可以通过调整一致性的代价来优化可靠性。
可用性:使用副本保证了数据的可用性。Cassandra通常会向不同的集群节点(通常为3)写入多个副本,如果一个节点不可用,数据也不会丢失。
将数据写入多个节点需要时间,因为节点分散在不同的位置。在某个时刻,数据最终将达成一致性。
所以,在优先考虑高可用性的情况下,就会降低一致性。
可调整的一致性:
对于读写操作,您可以指定一致性级别。一致性级别是指需要响应的副本数量,才能被视为读写操作已完成。
对于非关键特性,可以提供较低的一致性级别:例如1。如果您认为一致性很重要,可以将级别提高到TWO、THREE或QUORUM(大多数副本)。
假设您为关键功能设置了高一致性级别(QUORUM),并且大多数节点宕机。在这种情况下,写入操作将失败。
在这种情况下,Cassandra为了一致性而牺牲了可用性。
查看此文章以获取更多详细信息。