长话短说,我已经做过几个交互式软件的原型。我现在使用pygame(Python sdl wrapper),一切都在CPU上完成。我现在开始将它移植到C,同时寻找现有的可能性,以利用一些GPU的算力来减轻CPU的冗余操作。然而在我的情况下,我找不到好的“指南”应该选择什么样的技术/工具。我只是阅读了大量文档,这让我的精力迅速消耗殆尽。我不确定是否有可能,所以我很困惑。
这里我画了一个非常粗略的典型应用程序骨架草图,但是考虑到它现在使用了GPU(请注意,我几乎没有关于GPU编程的实际知识),数据类型和功能必须完全保留。这就是它:
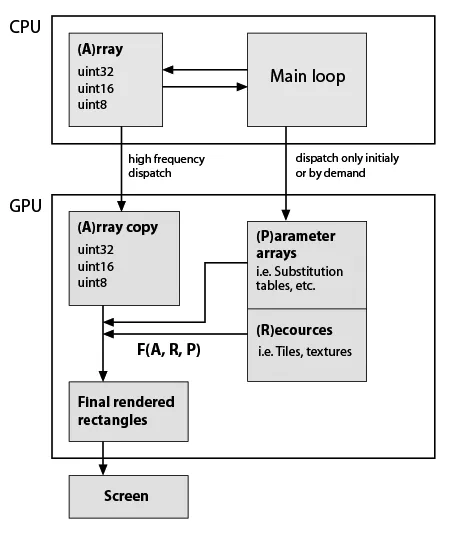 因此,F(A,R,P)是一些自定义函数,例如元素替换,重复等。该函数在程序生命周期内可能是恒定的,矩形形状通常不等于A形状,因此它不是原地计算。因此,它们只是通过我的函数生成的。 F的示例:重复A的行和列;用替换表中的值替换值;将一些图块组合成单个数组;在A值上进行任何数学函数,等等。如上所述,所有这些都可以在CPU上轻松完成,但应用程序必须非常流畅。顺便说一句,在纯Python中,添加了几个基于numpy数组的可视化功能之后,它变得不可用。 Cython有助于快速制作自定义函数,但是源代码已经有点像沙拉了。
因此,F(A,R,P)是一些自定义函数,例如元素替换,重复等。该函数在程序生命周期内可能是恒定的,矩形形状通常不等于A形状,因此它不是原地计算。因此,它们只是通过我的函数生成的。 F的示例:重复A的行和列;用替换表中的值替换值;将一些图块组合成单个数组;在A值上进行任何数学函数,等等。如上所述,所有这些都可以在CPU上轻松完成,但应用程序必须非常流畅。顺便说一句,在纯Python中,添加了几个基于numpy数组的可视化功能之后,它变得不可用。 Cython有助于快速制作自定义函数,但是源代码已经有点像沙拉了。
问题:
更新
这里是我位图编辑器原型的两个典型计算的具体示例。因此,编辑器使用索引,数据包括具有相应位掩码的层。我可以确定层的大小,掩码与层相同大小,例如,所有层都具有相同的大小(1024 ^ 2像素= 32位值的4 MB)。我的调色板有1024个元素(32 bpp格式的4千字节)。
考虑现在我想做两件事:
步骤1。 我想将所有层压平为一个。假设A1是默认层(背景),层“A2”和“A3”具有掩码“m2”和“m3”。在python中,我会写:
这里我画了一个非常粗略的典型应用程序骨架草图,但是考虑到它现在使用了GPU(请注意,我几乎没有关于GPU编程的实际知识),数据类型和功能必须完全保留。这就是它:
因此,F(A,R,P)是一些自定义函数,例如元素替换,重复等。该函数在程序生命周期内可能是恒定的,矩形形状通常不等于A形状,因此它不是原地计算。因此,它们只是通过我的函数生成的。 F的示例:重复A的行和列;用替换表中的值替换值;将一些图块组合成单个数组;在A值上进行任何数学函数,等等。如上所述,所有这些都可以在CPU上轻松完成,但应用程序必须非常流畅。顺便说一句,在纯Python中,添加了几个基于numpy数组的可视化功能之后,它变得不可用。 Cython有助于快速制作自定义函数,但是源代码已经有点像沙拉了。问题:
- 此模式反映了某些(标准)技术/开发工具吗?
- CUDA是我正在寻找的东西吗?如果是,请提供一些与我的应用程序结构相符的链接/示例。
更新
这里是我位图编辑器原型的两个典型计算的具体示例。因此,编辑器使用索引,数据包括具有相应位掩码的层。我可以确定层的大小,掩码与层相同大小,例如,所有层都具有相同的大小(1024 ^ 2像素= 32位值的4 MB)。我的调色板有1024个元素(32 bpp格式的4千字节)。
考虑现在我想做两件事:
步骤1。 我想将所有层压平为一个。假设A1是默认层(背景),层“A2”和“A3”具有掩码“m2”和“m3”。在python中,我会写:
from numpy import logical_not
...
Result = (A1 * logical_not(m2) + A2 * m2) * logical_not(m3) + A3 * m3
由于数据是独立的,我相信它必须按并行块的数量成比例地提高速度。
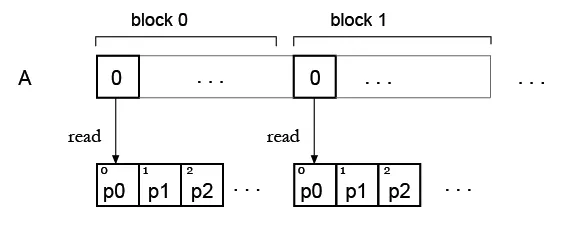
步骤 2。现在我有一个数组,并想用一些调色板进行“着色”,这将是我的查找表。从现在开始,我发现同时读取查找表元素存在问题。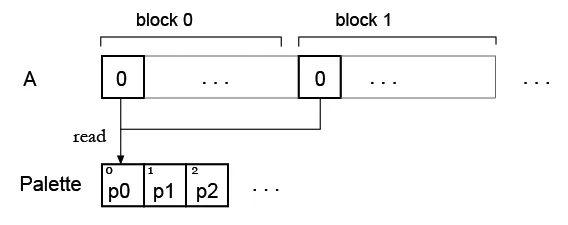
但是我的想法是,也许可以为所有块复制调色板,这样每个块都可以读取自己的调色板?像这样: