我有以下数据集,想要对每个国家和地区进行线性回归,然后将预测值添加到数据集中:
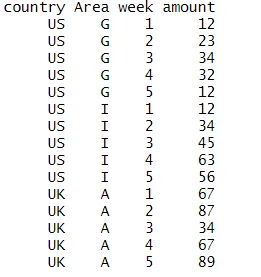 添加三列后的最终数据框如下:
添加三列后的最终数据框如下:
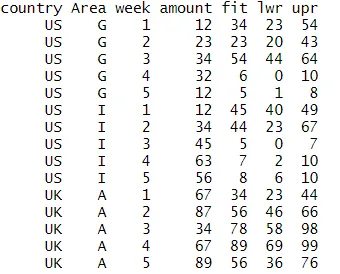 我已经为一个国家和一个地区完成了上述操作,但现在希望能对每个国家和地区都做一遍,并通过cbind将预测值、上限值和下限值放回到数据集中:
我已经为一个国家和一个地区完成了上述操作,但现在希望能对每个国家和地区都做一遍,并通过cbind将预测值、上限值和下限值放回到数据集中:
我该如何循环处理其他国家和地区的组合?
添加三列后的最终数据框如下:
我已经为一个国家和一个地区完成了上述操作,但现在希望能对每个国家和地区都做一遍,并通过cbind将预测值、上限值和下限值放回到数据集中: data <- data.frame(country = c("US","US","US","US","US","US","US","US","US","US","UK","UK","UK","UK","UK"),
Area = c("G","G","G","G","G","I","I","I","I","I","A","A","A","A","A"),
week = c(1,2,3,4,5,1,2,3,4,5,1,2,3,4,5),amount = c(12,23,34,32,12,12,34,45,65,45,45,34,23,43,43))
data_1 <- data[(data$country=="US" & data$Area=="G"),]
model <- lm(amount ~ week, data = data_1)
pre <- predict(model,newdata = data_1,interval = "prediction",level = 0.95)
pre
我该如何循环处理其他国家和地区的组合?
splitVar并将其用作split函数中的f会以两个变量进行拆分!非常直观的想法。 - Anoushiravan R