我仔细查看了Stack Overflow,但没有找到有用的结果。目前我甚至不确定这是否可能,但因为我只是一个初学者,所以我想至少在这里问一下。
基本上,我有多个数据集,每个数据集约有800万行,我不想循环每一行。我在多个地方读到过向量化几乎总是pandas DataFrame中最快的操作,但我无法想出一种不需要循环的编写脚本的方法。速度至关重要,因为我不想让我的电脑连续运行一个月。
我必须从一个DataFrame中取两个值,并将它们用作另一个DataFrame的索引,并将该值更改为1。假设以下代码:
使用for循环遍历range()迭代器似乎比iterrows()要快得多。但我希望让我的脚本尽可能地运行得更快(因为我有大量的数据),所以我想知道是否可以摆脱循环。我认为pandas模块有一种方法可以非常高效地完成这项工作,但我不知道是什么方法。
感谢任何帮助。
编辑:可能的重复问题并没有解决我的问题,因为我的目标不是将对角线值改为1;这只是一个巧合,因为我的示例非常简单。另外,如果我的编辑格式不正确,我很抱歉,我是新来社区的。
基本上,我有多个数据集,每个数据集约有800万行,我不想循环每一行。我在多个地方读到过向量化几乎总是pandas DataFrame中最快的操作,但我无法想出一种不需要循环的编写脚本的方法。速度至关重要,因为我不想让我的电脑连续运行一个月。
我必须从一个DataFrame中取两个值,并将它们用作另一个DataFrame的索引,并将该值更改为1。假设以下代码:
>>> import pandas as pd
>>> df1 = pd.DataFrame([[1,2],[3,4],[5,6]])
>>> df1.columns = ['A','B']
>>> df1
A B
0 1 2
1 3 4
2 5 6
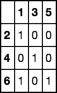
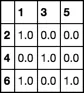
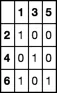
>>> df2 = pd.DataFrame(0, index = list(df1['B']), columns = list(df1['A']))
>>> df2
1 3 5
2 0 0 0
4 0 0 0
6 0 0 0
目前,我有一个像这样工作的for循环:
>>> listA = list(df1['A'])
>>> listB = list(df2['B'])
>>> row_count = len(listB)
>>> for index in range(row_count):
... col = listA[index]
... row = listB[index]
... df2[col][row] = 1
使用for循环遍历range()迭代器似乎比iterrows()要快得多。但我希望让我的脚本尽可能地运行得更快(因为我有大量的数据),所以我想知道是否可以摆脱循环。我认为pandas模块有一种方法可以非常高效地完成这项工作,但我不知道是什么方法。
感谢任何帮助。
编辑:可能的重复问题并没有解决我的问题,因为我的目标不是将对角线值改为1;这只是一个巧合,因为我的示例非常简单。另外,如果我的编辑格式不正确,我很抱歉,我是新来社区的。

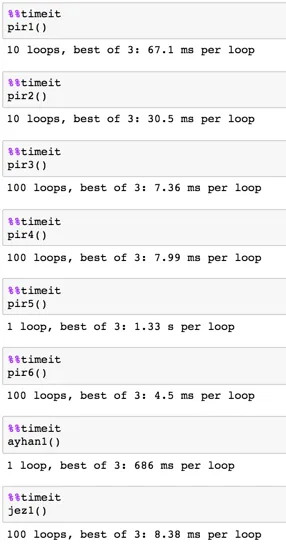
df2.loc[:, :] = 1,这会将数据框中的所有值都设置为 1。 - sirfzdf1中定义的索引对设置为1,而不是所有索引对。 - Andras Deak -- Слава Україні