假设我有一个包含标签列表或集合的DataFrame,我想根据某个标签是否是该行的一部分来过滤DataFrame,使用pandas实现最常用的方法是什么?
import pandas as pd
df = pd.DataFrame({
'amount': [15, 20, 40],
'tags': [["Food", "Eating Out"], ["Food", "Groceries"], ["Clothes"]],
'description': ["Garfunkel's", "Tesco", "Hollister"]
})
我有一段代码可以运行,但是写起来非常笨拙:
criterion = lambda row: 'Food' in row['tags']
df[df.apply(criterion, axis=1)]
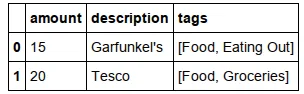
结果应该是:
pandas中,单个单元格中具有多个值并不是特别惯用的方式-我自己有时会这样做,但它使得使用典型的pandas习语变得非常困难。考虑到你目前的解决方案看起来相当不错,我不确定你能得到多少更好的解决方案。 - Marius