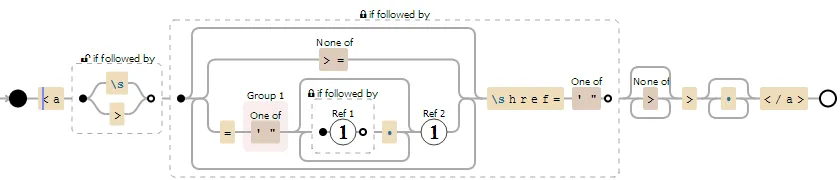
在Java中,我需要匹配字符串中没有href属性的<a>标签。例如在以下字符串中:
text <a class="aClass" href="#">link1</a> text <a class="aClass" target="_blank">link2</a> text
它不应匹配<a class="aClass" href="#">link1</a>(因为它包含href),但它应该匹配<a class="aClass" target="_blank">link2</a>(因为它不包含href)。
我成功构建了一个正则表达式来匹配我的<a>标签:
<a[^>]*>(.*?)</a>
但我不知道如何使用正则表达式消除带有href属性的<a>标签。
(我知道可以使用HTML解析器等工具,但我需要使用正则表达式来完成这个任务。)