我有这样的数据框:
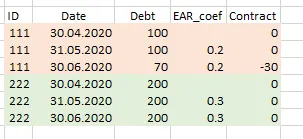
df = pd.DataFrame({'id': [111,111,111, 222,222,222],\
'Date': ['30.04.2020', '31.05.2020', '30.06.2020', \
'30.04.2020', '31.05.2020', '30.06.2020'],\
'Debt': [100,100,70, 200,200,200] , \
'Ear_coef': [0,0.2,0.2, 0,0,0.3]})
df['Date'] = pd.to_datetime(df['Date'] )
df['Contract'] = pd.DataFrame(df.groupby(['id']).apply(lambda x: x.Debt - x.Debt.shift(1))).reset_index().Debt
# df.groupby(['id']).
df
我需要得到这样的DataFrame:
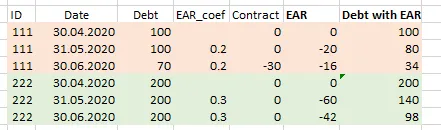
- 第一列是合同id
- 第二列是日期
- 第三列是预付款系数(EAR)
- 第四列是合同付款
- 第五列是EAR。它等于Ear_coef(t) * Debt_with_EAR(t-1)
- 第六列是Debt_with_EAR。它等于Debt_with_EAR(t-1)+Contract(t)+EAR(t)
我尝试使用apply方法解决此任务,但是由于需要使用先前计算的值,因此我并没有成功。 这些答案对我没有帮助Is there a way in Pandas to use previous row value in dataframe.apply when previous value is also calculated in the apply?,因为我有成百上千个id。
感谢您的帮助。
EAR依赖于Debt_with_EAR,而Debt_with_EAR又依赖于EAR。 - gosutoEar和Debt_with_EAR时,它们分别等于0和Debt。但是在第二天,我可以在开始时计算EAR,然后计算Debt_with_EAR。 - Roman