在书籍"Understanding and Using C Pointers"(作者:Richard Reese)的第85页中提到:
你可以在这里查看摘录。这一段是什么意思?在什么情况下会有编译器为这两个生成不同的代码?从基地址移动和添加到基地址之间有什么区别吗?我无法在GCC上实现这个,它生成了不同的机器代码。int vector[5] = {1, 2, 3, 4, 5};The code generated by
vector[i]is different from the code generated by*(vector+i). The notationvector[i]generates machine code that starts at location vector , movesipositions from this location, and uses its content. The notation*(vector+i)generates machine code that starts at locationvector, addsito the address, and then uses the contents at that address. While the result is the same, the generated machine code is different. This difference is rarely of significance to most programmers.

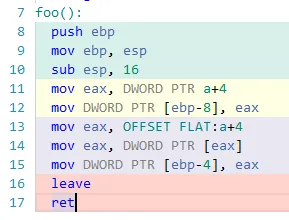
a[5]),编译器将生成不同的代码,因为它可以在编译时计算偏移量。但是,如果不知道翻译时i的值,我不明白a[i]和*(a+i)会有什么不同的处理方式。 - John Bodei的值,为什么a[i]和*(a + i)会有不同的处理方式” - 这样更好吗?我并没有将a[5]与*(a + i)进行比较。 - John Bode