如何在维护代码时遵循最佳实践和经验法则?将只有生产就绪的代码放在开发分支中是一种良好的实践吗?还是未经测试的最新代码应该在开发分支中可用?
你们如何维护你们的开发代码和生产代码?
编辑 - 补充问题 - 在向开发分支提交代码时,您的开发团队是否遵循“尽快提交并经常提交即使代码包含小错误或不完整”协议或“仅提交完美代码”协议?
如何在维护代码时遵循最佳实践和经验法则?将只有生产就绪的代码放在开发分支中是一种良好的实践吗?还是未经测试的最新代码应该在开发分支中可用?
你们如何维护你们的开发代码和生产代码?
编辑 - 补充问题 - 在向开发分支提交代码时,您的开发团队是否遵循“尽快提交并经常提交即使代码包含小错误或不完整”协议或“仅提交完美代码”协议?
2019年更新:
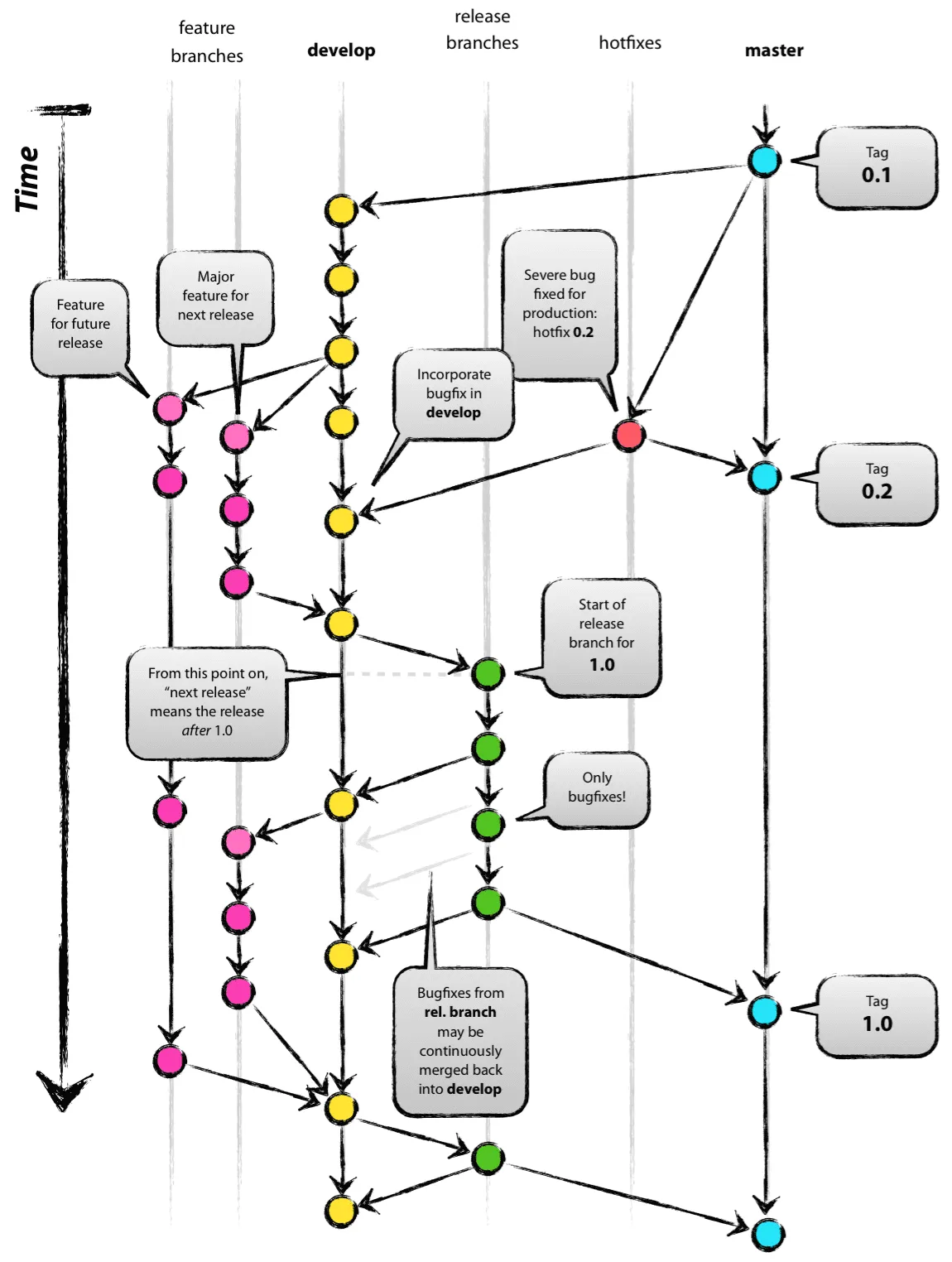
现在,这个问题常常会在使用Git的情境下出现,并且10年来使用分布式开发工作流程(主要通过GitHub协作)显示了一般最佳实践:
master是随时准备好部署到生产环境的分支:下一个发布版本,合并了特定功能分支的master。dev(或集成分支,或“next”)是测试下一个要发布的功能分支的分支maintenance(或hot-fix)分支是当前发行版演进/错误修复的分支,可能会合并回dev和/或masterdev合并到master,而是仅将特性分支合并到dev,然后如果选择,再合并到master,以便能够轻松删除未准备好进行下一个发布的特性分支)在Git存储库本身中实现,使用gitworkflow(一个单词,在这里说明)。请查看rocketraman/gitworkflow获取更多信息。与基于主干的开发相比,这种方法的历史记录在Adam Dymitruk的这篇文章的评论和讨论中有所提及。
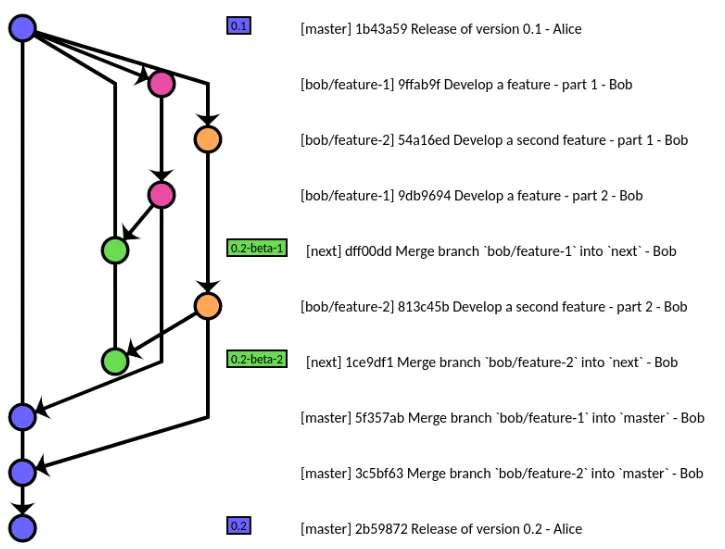
原始答案(2008年10月,已经超过10年)
这完全取决于您发布管理的顺序性质。
首先,您的主干中是否真的包含了下一个版本的所有内容?您可能会发现当前开发的一些功能:
在这种情况下,主干应包含任何当前的开发工作,但是在下一个版本之前定义一个发布分支可以作为合并分支,其中只合并适用于下一个版本的代码(经过验证),然后在同步阶段进行修复,并最终冻结以进入生产环境。
当涉及到生产代码时,您还需要管理补丁分支,同时要记住:
当涉及到开发分支时,您可以有一个主干,除非您需要进行其他并行的开发工作,例如:
现在,如果你的开发-发布周期非常顺序化,你可以像其他回答建议的那样去做:一个主干和几个发布分支。这适用于小型项目,其中所有开发都肯定会进入下一个版本并且可以被冻结,作为发布分支的起点,在此处可以进行补丁。这是名义上的过程,但是一旦你有了更复杂的项目...它就不再足够。
回答 Ville M. 的评论:
master(生产环境)和dev(集成环境)不会分歧?特别是在热修复时?你是否定期将master合并回dev,例如在发布后进行? - Bergigitworkflow。但我很高兴它仍然有用。 - VonC我们只使用开发分支,直到项目接近完成或我们正在创建里程碑版本(例如产品演示、演示版本),然后我们定期将当前开发分支分支成发布分支。
不会有新功能进入发布分支。只有重要的错误会被在发布分支中修复,而用于修复这些错误的代码会重新集成到开发分支中。
通过开发和稳定(发布)分支的两个步骤可以让我们的生活变得更加容易,我认为如果引入更多的分支,我们无法改善任何部分。每个分支也都有自己的构建过程,这意味着每隔几分钟就会产生一个新的构建过程,因此在进行代码检查后,大约半小时内就会得到所有构建版本和分支的新可执行文件。
偶尔我们也会为单个开发人员工作的新技术或创建概念验证而创建分支。但通常只有当更改影响到代码库的许多部分时才会这样做。这种情况平均每3-4个月发生一次,这样的分支通常在一个月或两个月内重新集成(或废除)。
通常我不喜欢每个开发人员都在自己的分支上工作,因为这会直接跳过集成工作而进入“集成地狱”。我强烈反对这种做法。如果你有一个共同的代码库,你们应该一起工作。这使得开发人员更加警惕他们的检查,在经验方面,每个编码人员都知道哪些更改可能会破坏构建,因此在这种情况下测试更加严格。
关于早期提交的问题:
如果要求只提交完美的代码,那么实际上什么都不应该提交。没有代码是完美的,而且对于QA来验证和测试它,需要将其放到开发分支中以便可以构建新的可执行文件。
对于我们而言,这意味着一旦开发人员完成并测试了某个功能,就会进行检查。即使存在已知的(非致命性)缺陷,它也可能被检查,但在这种情况下,通常会通知受到缺陷影响的人。未完成和正在进行中的代码也可以被检入,但只有在不会造成明显负面影响(如崩溃或破坏现有功能)的情况下才可以。
偶尔会出现无法避免的代码和数据混合检查,在新代码构建完毕之前程序将无法使用。最基本的做法是在检查注释中添加“等待构建”字样和/或发送电子邮件通知。
就我所知,这是我们的做法。
大多数开发都在主干(trunk)上进行,虽然实验性功能或可能会显著破坏系统的东西往往会有自己的分支。这样做效果不错,因为这意味着每个开发者在他们的工作副本中总是拥有最新版本的所有内容。
这也意味着保持主干的工作状态非常重要,因为它完全有可能彻底打破它。在实践中,这种情况并不经常发生,而且很少成为一个重大问题。
对于生产版本,我们从主干创建分支,停止添加新功能,并开始修复漏洞和测试该分支(定期合并回主干),直到准备好发布。在此之后,我们对主干进行最后合并以确保一切都在那里,然后发布。
随后可以根据需要在发布分支上执行维护,并可以轻松地将这些修复合并回主干。
我不断言这是一个完美的系统(它仍然存在一些漏洞-我认为我们的发布管理流程还不够紧密),但它已经足够好用了。
在分支上开发代码,将实时代码标记在主干上。
没有必要制定“只提交完美代码”的规则 - 开发人员遗漏的任何内容都应该在四个地方被发现:代码审查、分支测试、回归测试和最终QA测试。
以下是更详细的逐步说明:
哦,是的 - 还有一件事 - 我们将非生产代码(即永远不会发布的代码 - 例如工具脚本,测试实用程序)保留在cvs HEAD中。通常需要明确标记,以免有人“意外”发布它。
我使用git,有两个分支:master和maint
当我发布代码到生产环境时,我会打标签并将master合并到maint分支。我总是从maint分支部署。从开发分支中挑选补丁并将它们cherry-pick到maint分支中,然后部署补丁。