这是一个重要的问题,需要考虑很多因素。既然您没有提到任何具体的性能或架构限制,我会尝试提供最全面的建议。
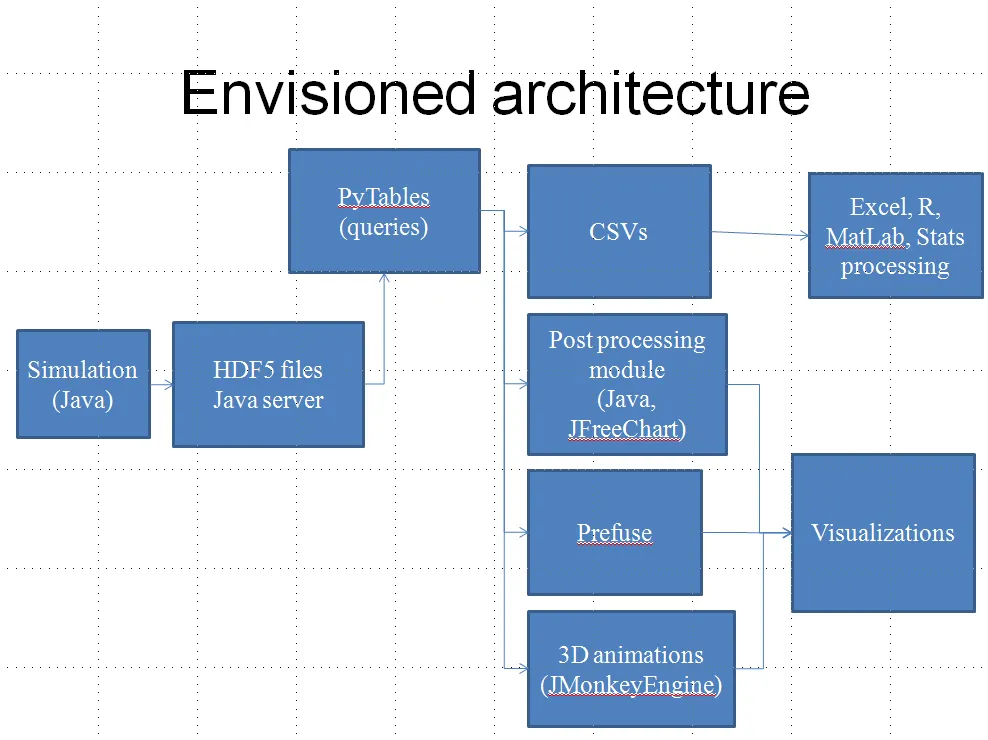
使用PyTables作为其他元素和数据文件之间中介层的初始计划似乎很稳健。但是,未提及的一个设计限制是所有数据处理中最关键的限制之一:哪些数据处理任务可以批量处理,哪些数据处理任务更像是实时流处理。
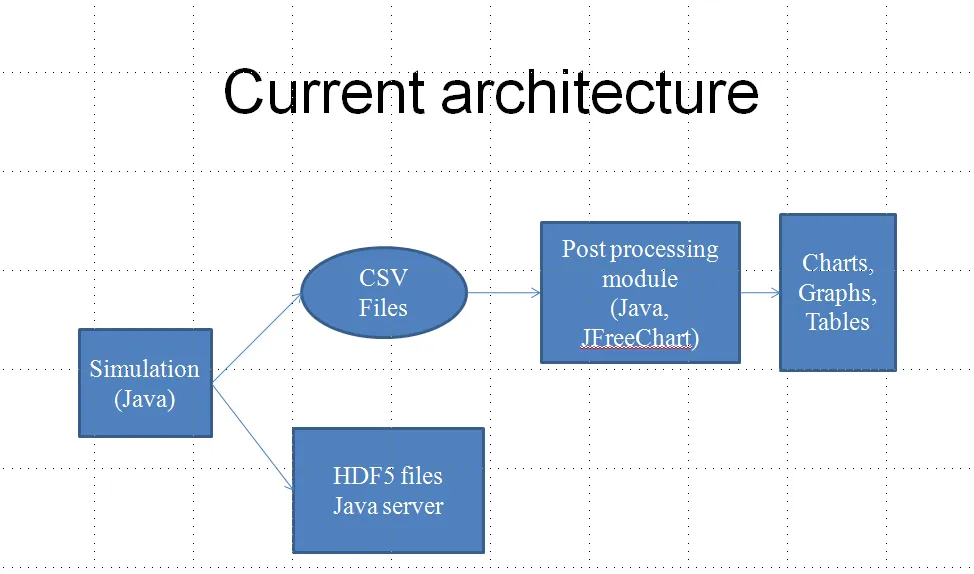
批量处理和实时流处理之间的这种区分对于架构问题来说至关重要。查看您的图表,有几个关系暗示不同的处理方式。
此外,在您的图表上,有不同类型的组件都使用相同的符号。这使得分析预期的性能和效率有点困难。
另一个重要的约束是您的IT基础设施。您是否拥有高速网络可用存储?如果是,中间文件成为在批量处理需求中分享基础架构各个元素数据的绝佳、简单且快速的方法。您提到在运行Java模拟的服务器上运行使用PyTables的应用程序。但是,这意味着服务器将承受写入和读取数据的负载。(也就是说,当无关软件查询数据时,模拟环境可能会受到影响。)
直接回答您的问题:
- PyTables看起来很匹配。
- Python和Java之间有许多通信方式,但请考虑采用无语言限制的通信方法,以便这些组件在必要时可以更改。这只是找到支持Java和Python的库并尝试它们一样简单。不管您选择使用任何库实现的API应该是相同的。(XML-RPC对于原型设计也是可以的,因为它在标准库中,Google的Protocol Buffers或Facebook的Thrift则是生产环境的好选择。但是,如果数据可预测且可批处理,请不要低估“将事物写入中间文件”的简单性。)
为了更好地帮助设计过程并明确您的需求:
很容易看待问题的一小部分,做出一些合理的假设,并进入解决方案评估阶段。但是,更好的方法是全面看待问题,并清楚地了解您的约束条件。我可以建议以下流程:
- 创建当前架构的物理和逻辑两个图表。
- 在物理图表上,为每个物理服务器创建一个方框,并绘制它们之间的物理连接。
- 请确保为每个服务器标记可用资源以及每个连接类型和可用资源。
- 如果有一些实际硬件并未用于当前设置但可能会有用,请将其包含在内。(如果您有一个可用的SAN,但没有使用它,请将其包括在内,以防将来可能需要。)
- 在逻辑图表上,为当前架构中运行的每个应用程序创建方框。
- 将相关库作为方框内部的组成部分包含在应用程序方框中。(这很重要,因为您的未来解决方案图表当前将PyTables作为一个方框,但它只是一个库,无法自主执行任何操作。)
- 将磁盘资源(如HDF5和CSV文件)绘制为圆柱体。
- 根据需要,将应用程序与其他应用程序和资源连接起来。始终从“操作者”到“目标”绘制箭头。因此,如果应用程序写入HDF5文件,则箭头从应用程序指向文件。如果应用程序读取CSV文件,则箭头从应用程序指向文件。
- 每个箭头都必须标记通信机制。未标记的箭头显示一种关系,但它们并不显示何种关系,因此它们无法帮助您做出决策或传达约束。
完成这些图表后,请制作几份副本,然后在上面进行数据流草图。针对需要原始数据的每个“终点”应用程序的每个图表副本,从模拟开始,以几乎连续的箭头流结束到终点。如果您的数据箭头横跨通信/协议箭头,请记录数据如何更改(如果有)。
此时,如果您和团队对纸张上的内容达成共识,则已经以一种易于传达给任何人的方式解释了当前架构。(不仅是在stackoverflow上的助手,还包括老板、项目经理和其他财务持有者。)
要开始规划您的解决方案,请查看数据流程图,并从终点向起点倒退,创建一个嵌套列表,其中包含返回起点的每个应用程序和中间格式。然后,列出每个应用程序的要求。请确保包括:
- 这个应用程序可以使用什么数据格式或方法进行通信。
- 它实际上需要什么数据。(始终相同还是根据其他要求随意更改?)
- 它需要多久才能得到它。
- 该应用程序大约需要多少资源。
- 该应用程序现在做的事情不太好。
- 这个应用程序现在能做什么是有帮助的,但它没有做。
如果您对此列表做得很好,您就可以了解如何定义所选择的协议和解决方案。 您查看数据穿过通信线路的情况,并比较通信两侧的要求列表。
您已经描述了一个特定的情况,在这种情况下,您有许多正在执行CSV文件中数据表“连接”的Java后处理代码,这是一个“现在需要但不太好”的功能。 因此,您查看该通信的另一侧,以查看另一侧是否可以很好地执行该操作。 目前,另一侧是CSV文件,而在此之前是模拟,因此没有任何东西可以在当前架构中更好地执行该操作。
因此,您提出了一个新的Python应用程序,它使用PyTables库来使该过程更好。 到目前为止,听起来不错! 但是在下一个图表中,您添加了许多其他与“PyTables”交谈的内容。 现在我们已经超出了StackOverflow团队的理解范围,因为我们不知道这些其他应用程序的要求。 但是如果您像上面提到的那样制作要求列表,您将确切地知道要考虑什么。 也许您的使用PyTables在HDF5文件上提供查询的Python应用程序可以支持所有这些应用程序。 也许它只支持其中一两个。 也许它为后处理器提供实时查询,但会定期为其他应用程序编写中间文件。 我们无法确定,但是通过规划,您可以。
一些最终准则:
- 保持简单! 复杂性是敌人。解决方案越复杂,实施起来就越困难,也越有可能失败。使用尽可能少的操作,使用尽可能简单的操作。有时,只需一个应用程序即可处理整个架构中所有其他部分的查询,这是最简单的方法。有时,一个应用程序用于处理“实时”查询,另一个应用程序用于处理“批量请求”更好。
- 保持简单! 这很重要!不要编写已经可以为您完成的任何内容。(这就是为什么中间文件非常好,操作系统处理所有困难的部分的原因。)此外,您提到关系型数据库的开销太大,但请考虑,关系型数据库还带有非常具有表现力且广为人知的查询语言,以及与之相对应的网络通信协议,并且您不必开发任何东西来使用它!无论您想出什么解决方案,都必须比使用现成解决方案更好,后者肯定会非常好,否则它就不是最佳解决方案。
- 经常参考物理层文档,以便了解您的考虑所需的资源使用情况。慢速网络链接或将太多内容放在一个服务器上都可能排除本来不错的解决方案。
- 保存这些文档。 无论您做出什么决定,您在过程中生成的文档都是有价值的。使用Wiki进行归档或存储它们,以便在下次需要时轻松查阅。
对于直接问题“如何让Python和Java相互协作?”,答案非常简单:“使用语言不可知的通信方法。” 事实上,Python和Java对于您所描述的问题集都不重要。重要的是流经其中的数据。任何能够轻松有效地共享数据的方法都可以正常运行。