我正在使用Python 2.7.9。我使用
但是,我甚至无法识别这些标签。
scipy.cluster.hierarchy.dendrogram来展示我的聚类结果。这里是Dendrogram。问题在于,我有大约200个数据,无法清楚地看到它们的标签。...
z=linkage(dist, method='complete')
R=dendrogram(z, labels=mylabels)
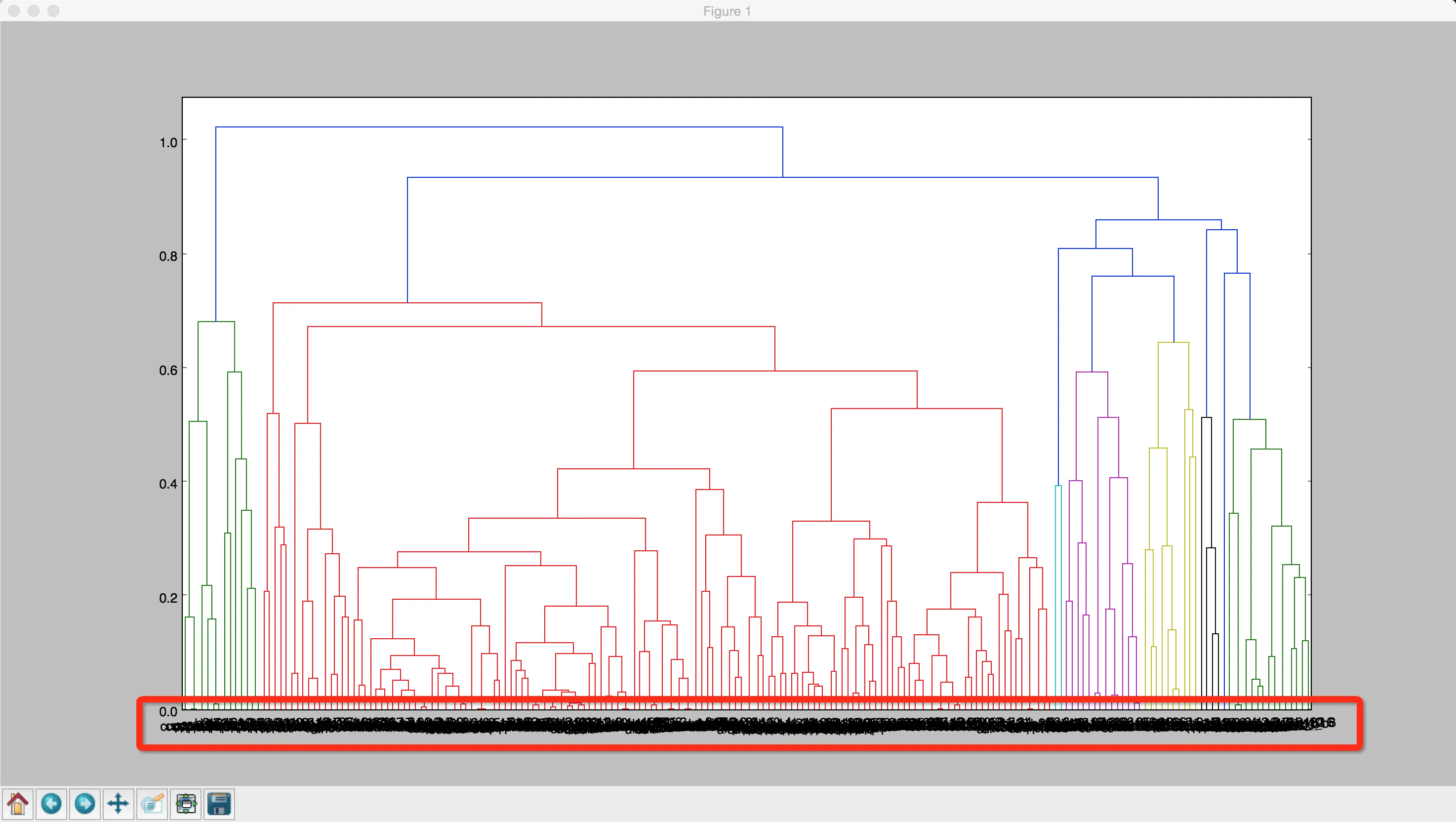
1.我知道R["ival"]对应于叶节点的标签,但在如此密集的图形中匹配值和数据并不容易。
2.我想提取数据的一部分。例如,左侧的绿色链接。在这个比例尺下,标签可以清晰地看到。我认为这是一种具有很大灵活性的分析数据的方式。但我不知道如何做到这一点。
3.我使用leaf_label_func。我的目标是:当数据真正属于一个类别--例如杯子--时,显示其名称/标签的一部分。例如,如果一个模型的名称为“cups_b1”,那么只显示“b1”。因此,至少我可以一次看到一类数据的位置。
def llf(id):
if id< nmodels:
mylabel=labels[id]
if mylabel.find("cups")!=-1:
index=mylabel.find("_")
outlabel=mylabel[index+1:]
return outlabel
else:
return "" #without the else part the function will return None, and that makes the output figure strange
R=dendrogram(z, leaf_label_func=llf, leaf_rotation=90 )
但是,我甚至无法识别这些标签。
